


Вступление
Каждый современный супермаркет содержит тысячи товаров, и у каждого товара должен быть свой ценник. Неправильный ценник под товаром распространённая проблема: покупатель может оказаться обманут в цене, а магазин рискует потерять доверие или нарушить закон. Обычно персонал проверяет соответствие товаров и ценников вручную, что трудоёмко и не всегда эффективно.
Здесь на помощь приходит компьютерное зрение. В этой статье мы расскажем о нашем опыте разработки системы автоматического сопоставления товаров и ценников на основе методов CV/ML. Мы опишем полный pipeline от детекции объектов на полке до OCR ценников и алгоритма matching (сопоставления ценников с товарами) – на примере реального кейса ритейла. Также поделимся тем, как мы преодолели сложности распознавания цен в полевых условиях с помощью специальных аугментаций и каких результатов добились.
Здесь на помощь приходит компьютерное зрение. В этой статье мы расскажем о нашем опыте разработки системы автоматического сопоставления товаров и ценников на основе методов CV/ML. Мы опишем полный pipeline от детекции объектов на полке до OCR ценников и алгоритма matching (сопоставления ценников с товарами) – на примере реального кейса ритейла. Также поделимся тем, как мы преодолели сложности распознавания цен в полевых условиях с помощью специальных аугментаций и каких результатов добились.
Pipeline: детекция, группировка, классификация
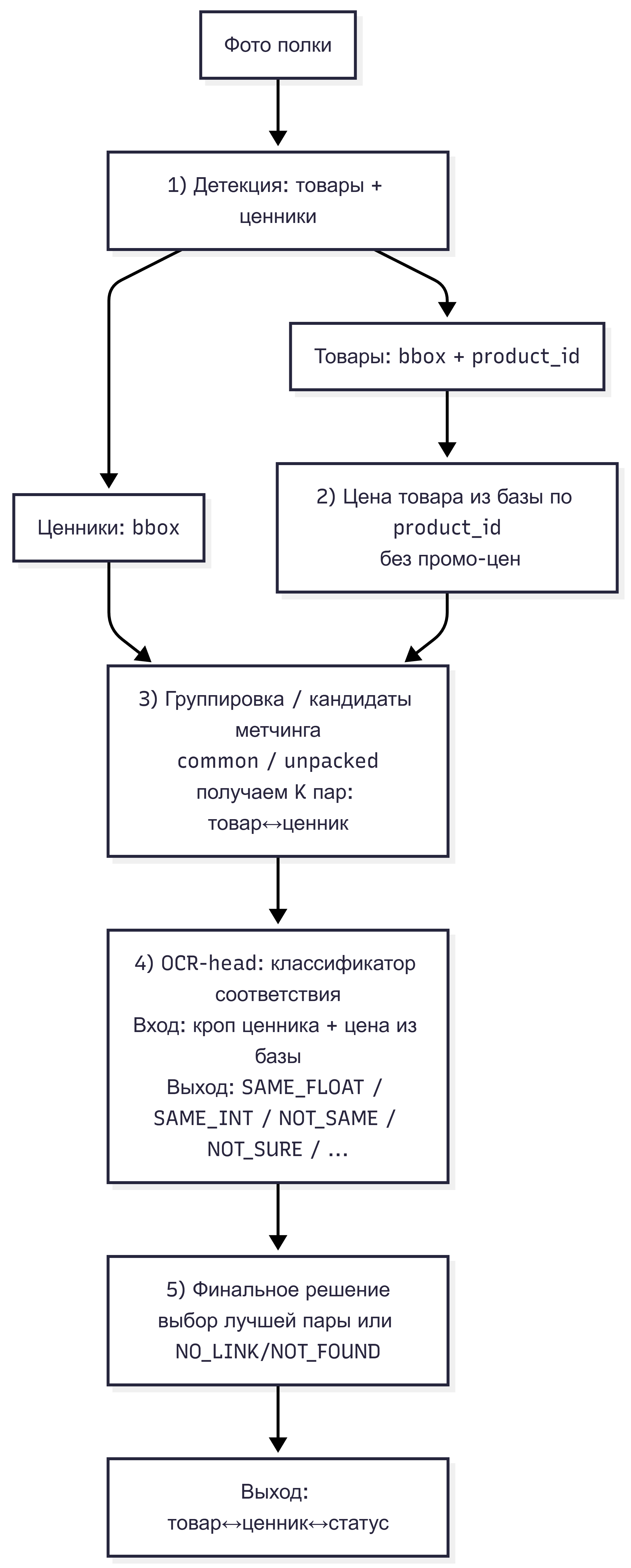
Чтобы решить задачу end-to-end, мы построили полноценный pipeline. Его основные этапы выглядели так:
- Детекция товаров и ценников. Первым шагом модель обнаруживает на изображении все товары и все ценники. Мы использовали модель объектного детектора (на базе свёрточной нейросети) и обучили её распознавать два типа объектов: product (товар) и price (ценник). На этом этапе каждому обнаруженному товару присваивается не только bounding box, но и product_id (идентификатор из каталога) – по сути модель классифицирует товар, определяя что это за продукт. Из product_id мы можем получить из базы данных известную цену этого товара. Ценникам же детектор просто рисует прямоугольники без распознавания текста. Детекция может работать с небольшими ошибками: иногда ценник не находится или находится лишний (кусок этикетки принять за ценник), но в целом задача детектора – покрыть максимум объектов для последующей проверки.
- Группировка ценников с товарами (matching candidates). После детекции нам нужно понять, какой ценник относится к какому товару. В простейшем случае на полке под каждой группой одинаковых товаров висит один соответствующий ценник – назовём это common strategy. Мы сопоставляем ценник ближайшему товару над ним. Если несколько товаров одного вида стоят в ряд, они все будут связаны с одним ценником. Однако бывают и более сложные случаи. Например, для неупакованных товаров (овощи, фрукты россыпью) ценник может находиться не прямо под каждым товаром, а один на весь ящик или группу. Мы реализовали специальные эвристики для таких ситуаций (“unpacked” стратегия): учитываем расстояние, ряд, а иногда и текстовое совпадение названия товара на ценнике. В итоге группировка формирует кандидаты: пары «товар–ценник», которые потенциально соответствуют друг другу и требуют проверки цены. Большинство ценников на этом этапе удаётся привязать к какому-то товару (или сразу к группе одинаковых товаров). Те ценники, что не удалось привязать по расположению, остаются без группы – их скорее всего модель потом классифицирует как not_found.
- Проверка цены: классификация соответствия. Ключевой этап – определить, совпадает ли цена на ценнике с ценой товара. Интуитивный подход: распознать OCR-движком число на ценнике, а затем просто сравнить с эталонной ценой товара из базы. Мы изначально рассматривали такой путь, но быстро отказались от него в пользу прямой классификации. Дело в том, что чтение OCR с ценников – вовсе не тривиальная задача: шрифт может быть мелким, подсветка неравномерной, иногда ценники помятые или засвеченные. Стандартные OCR-инструменты вроде Tesseract или облачных API показали низкую надёжность в наших тестах. Даже если OCR слегка ошибётся в цифре, то простое сравнение чисел даст неверный вывод (например, распозналось 129.99 вместо 128.99 – система решит, что цены не совпадают, хотя на самом деле на ценнике было 128.99). Кроме того, как быть, если ценник нечитаем? OCR в любом случае попытается выдать какие-то цифры, тогда как по логике нам нужно вернуть статус not_sure, а не неверное число. Мы пришли к выводу, что надёжнее обучить классификатор, который сразу выдаёт категорию соответствия– по изображению ценника и данным о цене товара. Такой подход учит модель фактически принимать решение о совпадении, минуя стадию явного чтения текста ценника. Чтобы структурировать задачу, мы разработали схему классификации состояния ценника, которая легла в основу разметки данных. Каждый ценник на изображении связывается с товаром (или товарами) и получает один из следующих статусов:
- same_float – цена на ценнике полностью совпадает с ценой товара (включая копейки). Например, и на товаре в базе, и на ценнике указано 119.99.
- same_int – совпадает только целая часть цены. Например, товар стоит 120.49, а на ценнике 120 (то есть копеечная часть не совпадает или не указана).
- not_same – ценник относится к данному товару, но цена не совпадает. Скажем, товар стоит 99.99, а ценник показывает 79.99 (мismatch).
- not_sure – ценник предположительно для этого товара, но само число на ценнике неразборчиво (размыто, повреждено и т.п.), так что нельзя уверенно сказать, совпадает цена или нет.
- double – на одном физическом ценнике указано две разных цены, и он соответствует сразу двум товарам (такое бывает, например, когда на одной этикетке перечислены два наименования товаров с разными ценами).
- not_found – невозможно однозначно решить, к какому товару относится ценник (дефолтный статус, когда связь не установлена).
Наш финальный подход выглядел так: мы вырезаем из фото фрагмент изображения ценника и подаём его в нейросеть-классификатор, совместно с ценой товара из базы (эталоном). Модель получает на вход визуальные признаки ценника и знание о том, сколько должен стоить товар, и выдаёт один из классов: same_float, same_int, not_same, not_sure или double/not_found. В реализации это сделано двумя потоками: CNN-экстрактор признаков для изображения ценника плюс векторные признаки, закодированные из числовой цены товара, объединяются и проходят через полносвязный классификатор. Итог – сеть сама учится понимать, совпадают ли числа, нужно ли игнорировать копеечную часть, или невозможно прочитать. Такой end-to-end классификатор оказалась устойчивее к шуму, чем последовательность “OCR -> сравнение”
4._Использование базы данных и ограничения. Для принятия решения нашему классификатору нужна правда о товаре – его цена. Эти данные мы берём из внешней базы (каталога) по product_id, распознанному на этапе детекции товара. Тут скрыт важный нюанс: база не содержит промо-цен. Т.е. в базе хранится обычно регулярная цена товара (например, 100 ₽), а если на полке сейчас акция и ценник показывает скидочную цену (скажем, 80 ₽), то с точки зрения системы это расхождение. В разметке такие случаи отмечаются как not_same (ведь цена отличается). Модель тоже обучается их предсказывать как not_same. Валидация показывает хорошую точность на них – но по факту это ложные тревоги: модель правильно видит, что ценник «не такой, как в базе», однако причина в маркетинговой акции, а не в ошибке. Мы возвращаемся к этому в разделе метрик – такая особенность данных осложняет интерпретацию результатов.
Почему не сравнение чисел, а классификация
Стоит подробнее остановиться на причине отказа от прямого сравнения чисел из OCR. Помимо упомянутых проблем с качеством распознавания, были и архитектурные соображения. Когда мы пытались пойти путём "детектировать текст -> преобразовать в число -> сравнить с эталоном", возникало множество разрозненных шагов, каждый со своей возможной ошибкой. Требовалось парсить строку OCR, учитывать символы вроде ',' или '.'для копеек, обрабатывать случаи вроде "ценник прочитан неуверенно" и задавать пороги уверенности. По сути, вокруг простого сравнения разрасталась бы сложная логика с правилами.
Классификационный же подход интегрирует всё в одной модели. Нейросеть самостоятельно учится выделять цифровые признаки на ценнике (то есть по сути выполняет скрытое OCR) и сразу сравнивать с нужным значением, поскольку задача сформулирована как категории совпадения. Мы передаем ей: "вот картинка, вот ожидаемая цена X" – а она должна вернуть, правильно это или нет. Такой подход ближе к человеческому: эксперт смотрит на полку и решает, тот ли ценник под товаром, не читая вслух каждую цифру. В итоге мы заметили значительный рост точности: снизилось количество случаев, когда мелкая ошибка чтения портила весь пайплайн. OCR для ритейла – это не просто распознавание числа, а принятие решения в условиях шума, и наш опыт это наглядно подтвердил.
Архитектура OCR-части: что мы выбрали и что дообучали
В проде мы сознательно разделили OCR-часть на три независимых компоненты:
- Модель чтения цены
- Scorer читабельности (качества кропа ценника)
- Candidate classifier для соответствия “ценник ↔ цена из базы”
1) Модель чтения цены
Для чтения цены мы выбрали простую и устойчивую схему “фиксированная длина → классификация цифр по позициям”.
- Backbone: timm resnet50d.ra4_e3600_r224_in1k
- Голова: один линейный слой, который выдаёт логиты размера num_heads × num_classes
- num_heads = 5 (позиции/разряды)
- num_classes = 11 (цифры 0–9 + спец-токен “стоп”)
Декодирование выглядит так: берём argmax по каждому разряду и обрываем последовательность на “стоп”-классе. Это даёт воспроизводимый и быстрый способ получить “цену как набор цифр”, без сложных seq2seq-конструкций.
2) Scorer читабельности
Отдельно мы держим scorer-модель, которая отвечает на вопрос: “Этот кроп ценника читаем или нет?”. Это практическая основа для ветки not_sure и для подбора порогов “читабельности”.
- Backbone: timm resnet18d...
- Выход: num_classes = 1 + sigmoid
3) Candidate classifier вместо “OCR → парсинг → сравнение”
Самый важный компонент пайплайна это candidate classifier, который заменяет хрупкую цепочку “прочитали число, распарсили, сравнили”.
Он решает задачу как классификацию соответствия по входам:
- кроп ценника
- цена-кандидат из базы
Цену-кандидат мы кодируем как цифры целой и дробной части через one-hot:
- 11 классов (цифры 0–9 + паддинг цифрой 10)
- max_len = 5
Дальше делаем небольшой эмбеддер для кандидата: Linear(11 * max_len → 256) и конкатенируем его с визуальными фичами resnet50d. После этого идёт компактная MLP-голова с ReLU и Dropout(0.2), которая выдаёт класс соответствия. В актуальной версии после мерджа неопределённых классов это 3 класса: SAME, NOT_SURE, NOT_SAME.
Ключевой инженерный приём, который дал прирост: candidate classifier инициализируется весами backbone из OCR-чекпоинта. Мы загружаем только слои backbone.*, то есть переносим “понимание цифр” из задачи чтения в задачу сравнения с кандидатом.
Препроцессинг и воспроизводимость
Пайплайн держим максимально стандартным и воспроизводимым:
- Resize до фиксированного img_size
- Normalize как у ImageNet
- конфигурации и параметры тянутся из Hydra-конфигов
- чекпоинты версионируются под продовые релизы
В результате мы дообучали не “ещё один OCR”, а именно голову принятия решения в шумных условиях.
Аугментации и обучение класса not_sure
Мы подошли к not_sure не как к “ещё одному классу”, а как к отдельной проблеме данных. Изначально разметка была сделана с перекрытием и голосованием: один и тот же пример размечали несколько человек, после чего мы агрегировали голоса в финальный лейбл. На практике это быстро выявило особенность: когда ценник хоть немного спорный, разметчики часто уходят в безопасный вариант и ставят not_sure. В итоге в сырых голосах not_sureочень часто становился “победителем”, даже если часть людей всё-таки смогла прочитать цену и определить совпадение или несовпадение.
Чтобы не превратить not_sure в мусорную корзину для всего сложного, мы сделали более строгую агрегацию голосов. Правило получилось таким: если среди голосов есть хотя бы два из восьми за “уверенные” классы (то есть same или not_same, когда человек реально увидел цену), то мы перевешиваем итоговую метку в пользу same или not_same, даже если по большинству голосов лидировал not_sure. Логика простая: два независимых разметчика, которые прочитали ценник, обычно означают, что ценник всё-таки читаем, и модель должна учиться на этом как на “видимом” сигнале, а не уходить в not_sure.
После такой агрегации возникла вторая проблема. Мы стали лучше отделять “читаемые” случаи от нечитабельных, но при этом настоящих not_sure стало меньше, и разнообразие “реально не видно” оказалось ограниченным. А именно на этих примерах модели нужно учиться правильно останавливаться и не путать нечитаемость с not_same.
Поэтому мы усилили именно класс not_sure через аугментации. Источник для этого класса мы брали из двух корзин:
- реальные not_sure, где ценник действительно не читается;
- часть примеров из same, которые можно “деградировать” до состояния, когда цену уже невозможно надёжно разобрать.
Мы генерировали дополнительные not_sure примеры, ухудшая кропы ценников до реалистичного “полевого” состояния. В ход шли сильные искажения, которые воспроизводят то, что мы видим в проде: размытие, шум, потеря резкости, частичные перекрытия и обрезки, а также характерные засветки. Цель этих аугментаций была не в том, чтобы “сделать модель сильнее на OCR вообще”, а в том, чтобы чётко выстроить границу: когда ценник уже нельзя читать, правильный ответ это not_sure, а не “угадывание” между same и not_same.


На валидирующем наборе мы отдельно проверяли, что после такого подхода модель стала реже уходить в ложный not_same на плохих кропах и лучше выделяет настоящую нечитаемость. Для нас это было ключевым: not_sure должен означать “реально не видно”, а не “сложно, поэтому безопасно”.
Двойные ценники – сложность вне MVP
Отдельная категория — double, ценник с двумя разными ценами (и часто двумя названиями товаров мелким шрифтом). В разметке такие случаи помечены, и наш классификатор в принципе может попытаться их выявить. Мы включили класс double в обучение, однако честно признаемся: в продуктовой версии системы пока нет особой логики обработки таких ситуаций. Почему? Двойной ценник существенно усложняет pipeline: выходит, один bounding box ценника связан сразу с двумя товарами. Нужно либо разбивать область ценника на две зоны и распознавать каждую отдельно, либо после детекции ценника делать дополнительную классификацию, чтобы понять, что он двойной, и только потом сопоставлять с товарами. Мы решили, что частота таких случаев невелика и для MVP можно их пропустить (например, всегда помечать как not_found или not_same). В будущих итерациях, конечно, хотелось бы и это покрыть — вероятно, дополнительной моделью, которая детектирует сегменты внутри ценника (две цены) или end-to-end моделью, сразу выдающей пару цен. Но на начальном этапе мы сознательно ограничили область задачи, чтобы не раздувать сложность.
Стоит отметить, что метрики по классу double валидации не особо информативны из-за малого числа примеров. Модель может даже выучить несколько шаблонов таких ценников и получать высокий precision, но практической пользы, пока мы их не обрабатываем отдельно, от этого мало. Мы смотрели на эти случаи вручную и учитывали, что пока ошибочные срабатывания по double для нас не критичны.
Метрики и калибровка уверенности
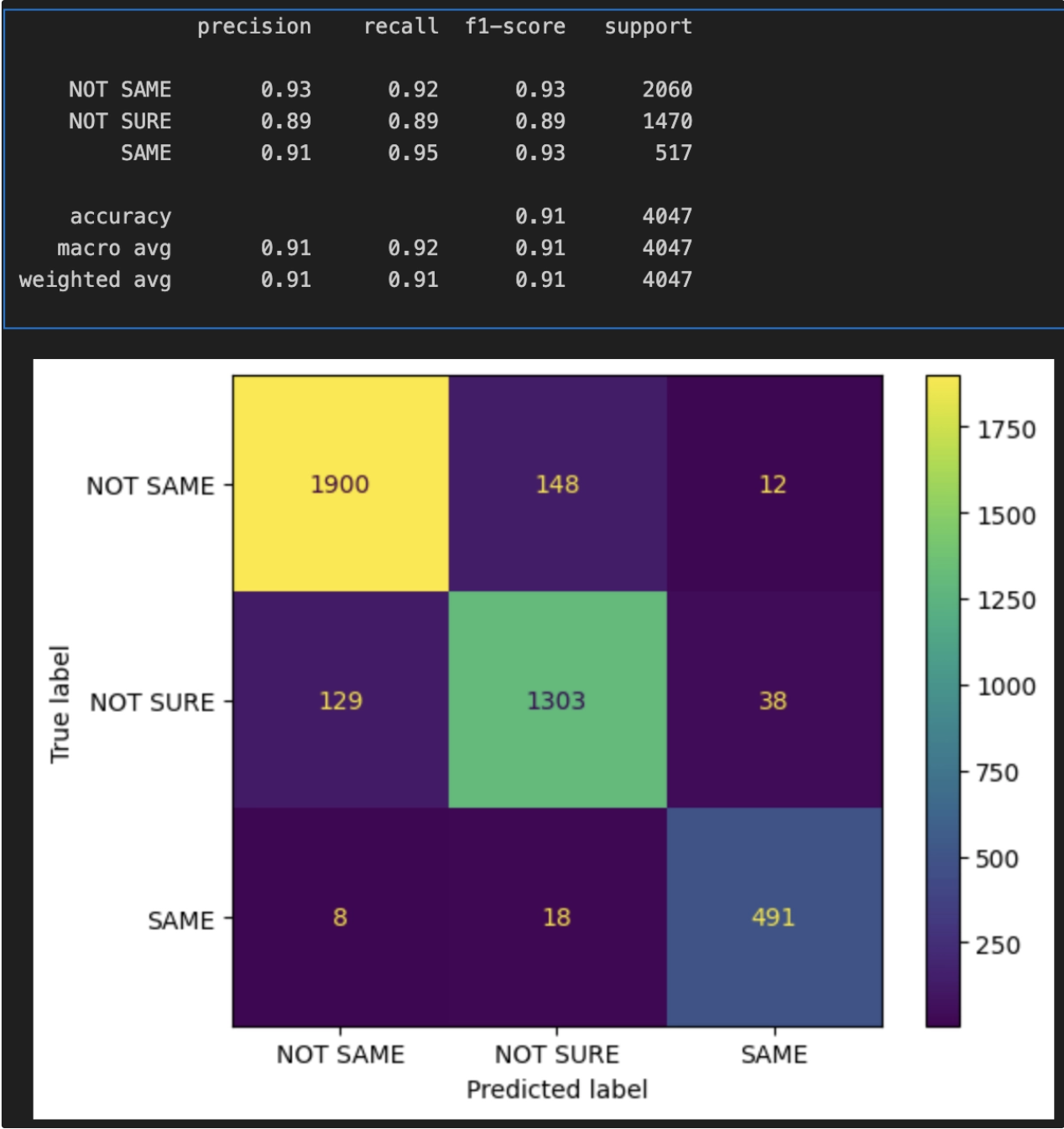
Для оценки качества модели мы использовали стандартные метрики классификации: Accuracy и F1-score по каждому классу. Общая accuracy на валидационном наборе превысила 91%, что для нашей шестиклассовой задачи было хорошим результатом. Однако более показательно смотреть на разбивку по классам.
- Совпадения (same_float/same_int) модель научилась угадывать лучше всего – F1 этих классов ~0.93. Оно и понятно: примеров полно, сигнал однозначный. Ошибки случались в основном на границе между float/int: иногда модель путала полное совпадение с совпадением по целой части. Например, ценник "100" против цены 100.00 – по логике это same_float (полное совпадение, просто на ценнике нет копеек), но модель могла ошибочно отнести к same_int. Мы потом подкрутили разметку и логику, чтобы такие случаи тоже учесть как float.
- Несовпадение (not_same) тоже давалось достаточно уверенно (F1 ~0.9). Здесь основная путаница происходила с классом not_sure. Изначально модель иногда выдавала not_same там, где ценник просто плохо читаем. После введения агрессивных аугментаций эта проблема уменьшилась: доля правильных not_sureвыросла, а лишних not_same снизилась. Мы фактически научили сеть: если очень не уверен – лучше скажи not_sure, чем not_same. Это важный для продукта момент, ведь not_same – это сигнал ошибки (например, неправильно установлен ценник), и ложноположительные срабатывания тут особенно нежелательны.
- Неуверенные случаи (not_sure) удалось вычленять с приемлемой точностью (F1 ~0.89). Поведение модели мы дополнительно проверяли вручную: просматривали картинки, где модель говорит not_sure, и убеждались, что действительно там читать цифры тяжело. Иногда модель всё же путала not_sure и not_same в сложных случаях, но в целом стала довольно консервативной – и это скорее плюс для нашего применения.
Визуализации и метрики сопоставления товаров и ценников
Распознать цену это только полдела. Дальше нужно решить, правильно ли этот ценник относится к конкретному товару, и если относится, то что именно мы про него можем сказать. Для формализации мы использовали классы соответствия, но в продуктовой аналитике свели их к четырём группам и фокусировались на двух “самых ценных” для бизнеса.
Класс A (SAME) это однозначное соответствие: мы нашли правильный метч “товар ↔ ценник”, на ценнике читается цена, и она согласуется с числом-кандидатом из базы. В терминах разметки это покрывает случаи, когда мы уверенно понимаем, что перед нами “его” ценник и он корректен.
Класс B (NOT_SAME) это тоже однозначная связь “товар ↔ ценник”, но цена на ценнике не соответствует числу из базы. Важно, что здесь мы не про ошибку линка. Мы уверены, что ценник относится к этому товару, но число расходится. В реальном проде в этот класс часто попадают акционные ценники, потому что промо-цен в базе нет, и модель корректно фиксирует “не совпало с источником”.
Класс C (NOT_FOUND / NO_LINK) это отсутствие связи. Мы не смогли уверенно сопоставить ценник ни с одним товаром
Класс D (NOT_SURE) это случаи, когда связь “ценник ↔ товар” вероятнее всего есть, но по изображению нельзя уверенно прочитать или подтвердить цену.
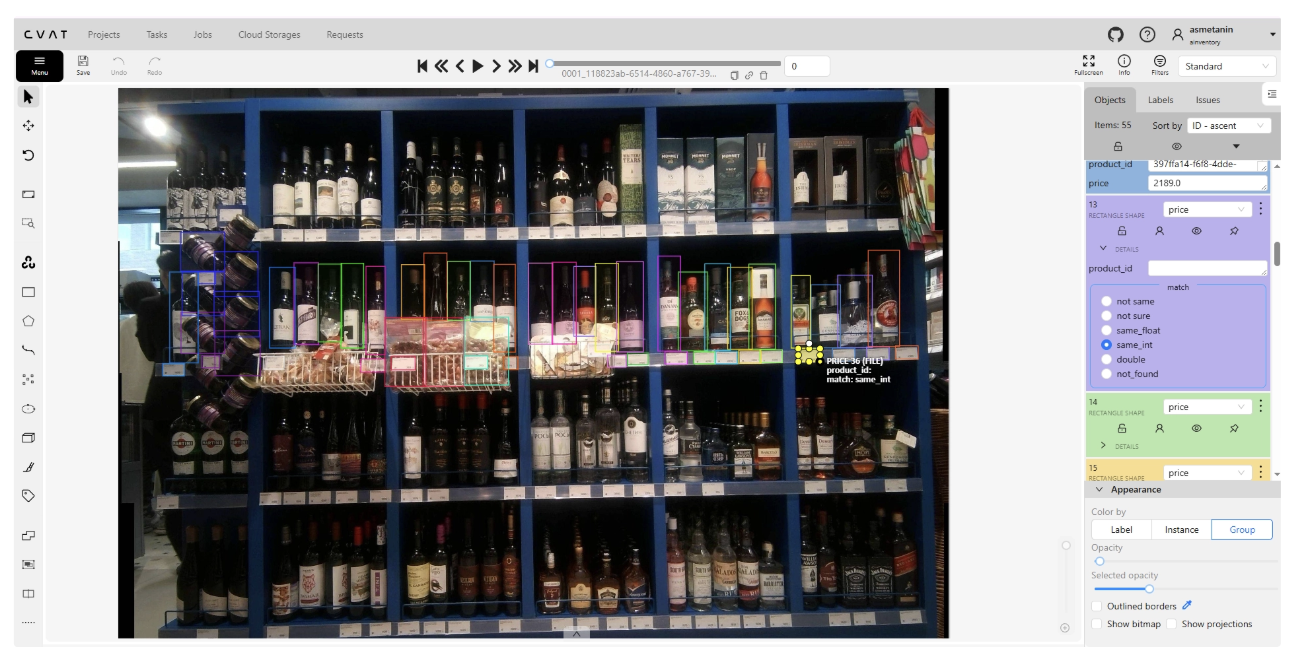
Чтобы честно считать end-to-end качество, мы делали отдельную ручную разметку E2E. Разметчик смотрел на кадр и отмечал те метчи “товар ↔ ценник”, которые он реально видит, а затем проставлял класс соответствия (A/B/C/D). Это позволило оценивать систему не по отдельным модулям, а по итоговому поведению на полке.
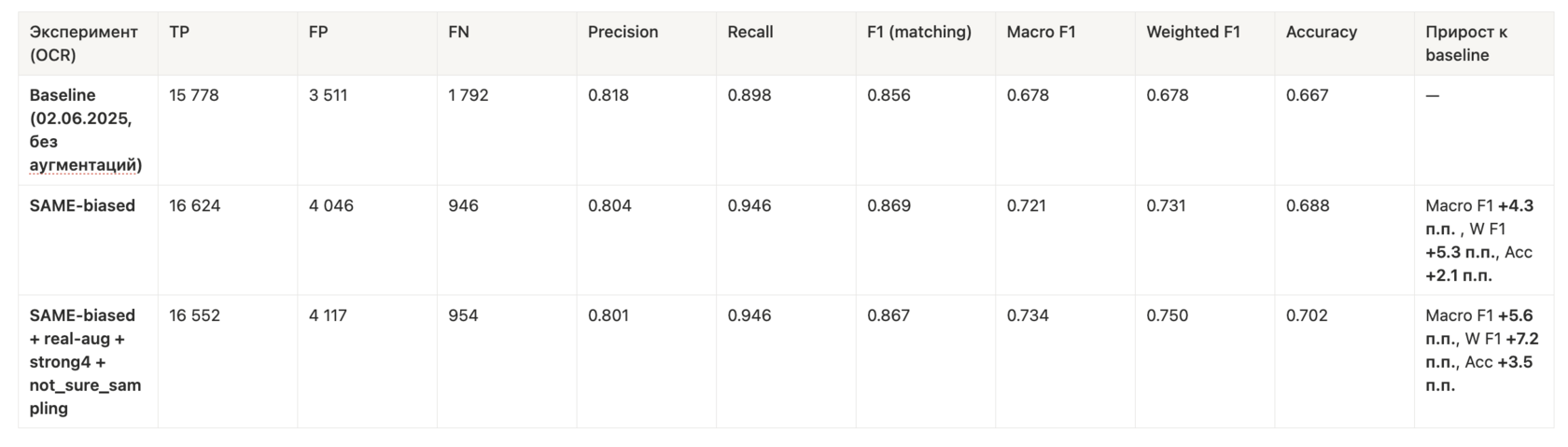
Ниже приведены метрики матчинга для разных моделей. у нас две метрики одна на метрика на метчинг(товар ценник) другая метрика на метчинг + выбор класса.
Теперь, когда мы разобрали цифры и видно, как менялось качество метчинга от версии к версии, хочется “приземлить” метрики на реальные кадры. Одно и то же значение Macro F1 может складываться из очень разных ошибок, и понять это по таблице невозможно. Поэтому дальше покажу несколько типовых примеров работы алгоритма на фотографиях полок.

Выводы
Мы разработали решение, которое автоматически проверяет соответствие ценников и товаров на полочных фотографиях. Пайплайн включает детекцию объектов, группировку ценников с товарами и специальный классификатор, решающий, совпадает цена или нет. Благодаря комбинированному подходу (визуальные признаки + известная цена товара) модель достигает высокой точности и умеет сообщать о неуверенности вместо того, чтобы ошибаться. В ходе проекта мы сделали несколько важных выводов:
- End-to-end классификация vs стандартный OCR: Наш опыт показал, что для задачи в ритейле прямое распознавание текста – не панацея. Куда эффективнее сразу учить модель на конечную цель (правильно/неправильно), чем разбирать по частям (читать цифры, а потом сравнивать). Такой подход оказался устойчивее к шумам и вариациям условий съёмки. По сути, мы реализовали специализированный OCR, заточенный именно под ценники и их проверку, поскольку общие OCR-движки не справляются идеально.
- Важно обрабатывать неуверенность. В реальных условиях некоторые ценники невозможно распознать даже человеку. Система должна уметь выявлять такие случаи и помечать их как требующие ручной проверки (not_sure). Мы добились этого сочетанием разметки и аугментаций. Это снижает ложные тревоги и фокусирует внимание человека на действительно проблемных местах. Лучше сообщить "не уверен" и позвать человека, чем уверенно сообщить неправильный результат.
- Iterate fast, then refine: Начав с MVP, мы сознательно отложили сложные случаи (типа двойных ценников) на потом. Это позволило быстрее довести систему до рабочей стадии и получить обратную связь. Постепенно можно наращивать функциональность, добавлять новые классы или правила.
В итоге, автоматизация проверки ценников оказалась нетривиальной, но решаемой задачей. В дальнейшем мы планируем улучшать модель, добавлять учёт акций и обрабатывать все граничные случаи. Надеемся, этот кейс был полезен для ML/CV специалистов, кто сталкивается с похожими проблемами. Мы убедились, что даже задача, на первый взгляд сводящаяся к чтению числа, требует комплексного подхода с учётом контекста и неопределённости – и именно такие нюансы делают работу инженеров машинного обучения настолько интересной.
Огромное спасибо нашим инженерам, Александру Коротаевскому и Артему Сметанину, за подготовленную статью.

