


Точные и быстрые системы распознавания маркировки на товарах позволяют оптимизировать процессы, связанные с логистикой, складированием и розничной торговлей. Однако для того, чтобы гарантировать высокое качество работы таких систем, важно оценивать их производительность через метрики качества.
Итак, у нас есть система распознавания маркировки, которая работает в режиме реального времени и с помощью которой мы распознаем двумерные коды (Data Matrix, QR-код) и товарные знаки на товарах.
Процесс работы достаточно прост. Пользователи сканируют товары – будь то бутылка, пачка сигарет или упаковка лекарства – простым наведением камеры смартфона. Сканирование определяет различные виды маркировок, ключевые из которых – это двумерный код:
- Data Matrix
- QR-код
Основной фокус нашей работы сконцентрирован на распознавании Data Matrix, которая широко используется для маркировки и контроля подлинности товаров. Ряд продуктов в России подвергается обязательной маркировке, и число таких продуктов только растет.
К Data Matrix продукта привязана различная информация, включая сроки годности, серийные номера и уникальные идентификаторы. Например, при приеме партии молочной продукции сканируется Data Matrix, чтобы проверить подлинность продукта, срок годности и другие показатели. Сбои в распознавании ведут к ошибкам, задержкам и убыткам, связанным с ними. Поэтому качество выполнения работы системой стоит особенно остро.
Когда речь заходит о работе системы в реальном времени на мобильных устройствах, возникает несколько сложных задач:
- Как измерить скорость работы системы?
- Как измерить точность распознавания в разных условиях и на разных устройствах?
- Как отслеживать прогресс улучшений при разработке новых версий системы?
С помощью ETL-библиотеки Datapipe мы разработали пайплайн для автоматического расчета метрик качества распознавания маркировки, которые гарантируют своевременную реакцию на любые сбои в распознавании и их устранение. Таким образом мы поддерживаем высокую точность распознавания маркировки нашими моделями.
Технологии
Datapipe - ETL с автоматическим трекингом зависимостей данных, которая позволяет эффективно пересчитывать только измененные данные в коде. Используется для обучения моделей детекции и классификации.
MediaPipe - библиотека машинного обучения от Google для реализации задач компьютерного зрения, используемая для обработки видеопотока с камеры в реальном времени.
MLFlow – платформа для управления машинным обучением. Используется для логирования и отслеживания метрик качества работы системы распознавания. С ее помощью сравниваем результаты работы различных версий алгоритмов, анализировать эффективность обновлений и контролировать стабильность системы.
Зачем нужны метрики качества?
Метрики качества необходимы для объективной оценки работы системы распознавания. Основные вопросы, которые они помогают решить:
- Распознает система маркировку или нет?
- Насколько точно система распознает маркировку на изображении или видео?
- С какой скоростью происходит распознавание?
- Какое количество объектов удается распознать за заданный период времени или за определенное количество кадров?
- Насколько качественно работает система с учетом различных сложностей: размытия изображения, частичного перекрытия маркировки или плохого освещение?
Все эти метрики помогают разработчикам понять, насколько система готова к использованию, какие компоненты нуждаются в улучшении, и какова эффективность внедрения новых версий алгоритмов.
Что такое Datapipe и как мы ее используем?
В своем проекте мы используем инструмент с открытым исходным кодом Datapipe.
Datapipe — это ETL-библиотека, которая позволяет собирать, обрабатывать и анализировать данные с поддержкой трекинга зависимостей. Одно из ключевых преимуществ использования Datapipe — это инкрементальная обработка данных, благодаря которой подсчитываются метрики только для измененных данных или обновленного кода, сохраняя результаты предыдущих обработок. Это означает, что если в систему были добавлены новые видеозаписи или была обновлена кодовая база, пересчитываться будут только те данные, которые были изменены.
Представим, что у нас есть новая группа товаров — 20 видеозаписей, которые необходимо добавить к уже обработанным 100 видео. Вместо того чтобы запускать процесс с самого начала, Datapipe позволит нам просто добавить эти новые данные в пайплайн и с помощью Mediapipe и MLFlow пересчитать метрики только для этих 20 видео, не затрагивая уже обработанные видеозаписи.
Пересчитывая только необходимые данные, мы экономим время и ресурсы, а результаты работы предыдущей версии сохраняются для сравнения.
Архитектура пайплайна для расчета метрик
Мы решили подсчитать метрики качества распознавания маркировки на товарах, с которыми уже были трудности распознавания. Для проведения оценки мы собрали набор изображений, состоящий из 1000 Федеральных Специальных Марок (алкоголь), 1000 никотиносодержащих продуктов и 1000 мягких упаковок для анализа специфических искажений. Эта категория товаров была выбрана по причине частых ошибок в распознавании.
1. Сбор данных
Сбор данных ведется с помощью платформ, таких как Ozon и Яндекс.Толока, где подрядчики фотографируют и снимают видео продуктов с двумерными кодами.
Для каждого товара создается статичное изображение и видео, чтобы учитывать реальные условия использования, когда пользователь может вращать продукт перед камерой. Эти фото и видео-изображения затем загружаются в пайплайн системы.
2. Детекция и классификация
Каждое видео прогоняется через пайплайн, в котором детектор распознаёт двумерные коды на каждом кадре, а классификатор применяет соответствующие фильтры и улучшения (например, улучшение контраста, подавление бликов, сглаживание артефактов). Нередко с этой целью используется бинаризация: процесс превращения серых пикселей в черные или белые помогает устранить блики и другие искажения, особенно на защитных пленках. Это позволяет определить, насколько улучшения предобработки влияют на точность и скорость распознавания.
3. Распознавание и оптимизация
Пайплайн учитывает разные конфигурации, так как обработка изображений и видео требует различных подходов. Например, для видео в реальном времени важна скорость, в то время как для изображений можно применять дополнительные фильтры для улучшения качества.
Для эффективности в работе с различными типами данных, пайплайн использует адаптивный подход. Он автоматически выбирает параметры обработки в зависимости от особенностей входного материала и целей анализа. При работе с изображениями и видео учитываются такие факторы, как освещение, контрастность и детализация.
Приступаем к модификации алгоритма. Новая версия алгоритма фокусируется на специфических улучшениях для Data Matrix с дефектами печати. Этот алгоритм проверяет целостность заштрихованных полос и применяет дополнительные патчи для распознавания кодов с разрывами в структуре.
4. Подсчет метрик
- Подсчет метрик на разных версиях данных и кода. MLFlow собирает данные о точности, скорости распознавания и числе распознанных объектов, что позволяет сравнивать текущие результаты с предыдущими версиями алгоритмов.
- Автоматический расчет метрик распознавания для всех версий данных и кода. Это даёт возможность:
- Сравнить текущие результаты (на обновленной кодовой базе) с предыдущими.
- Оценить влияние обновлений алгоритма на каждый набор данных.
- Создание таблиц метрик. Результаты подсчета сохраняются в виде таблиц с показателями для старой и новой версии алгоритма на каждом наборе данных. Пайплайн автоматически обновляет только те метрики, которые связаны с измененными данными или кодом, что упрощает контроль качества и анализ эффективности алгоритмов.
5. Сравнение версий и анализ результатов
Оценка каждой версии алгоритма проводится по ряду метрик, чтобы выбрать оптимальные решения для конкретных категорий продуктов и выявлять успешные улучшения.
В завершение, проводим анализ результатов. Он включает:
- Сопоставление метрик текущей и предыдущих версий для выявления влияния изменений.
- Выявление аномалий, обнаружение резких изменений в метриках и проверка стабильности по разным наборам данных.
- Анализ причин изменений и поиск решения по улучшению системы.
- Оценка того, как обновления влияют точность и скорость распознавания.
Частые проблемы и их решение

1. Разрывы L-паттерна
Одной из первых проблем, с которой мы столкнулись было распознавание L-паттерна с дефектом на Data Matrix. При распознавании DataMatrix-кодов одной из главных задач является корректное определение L-паттерна.
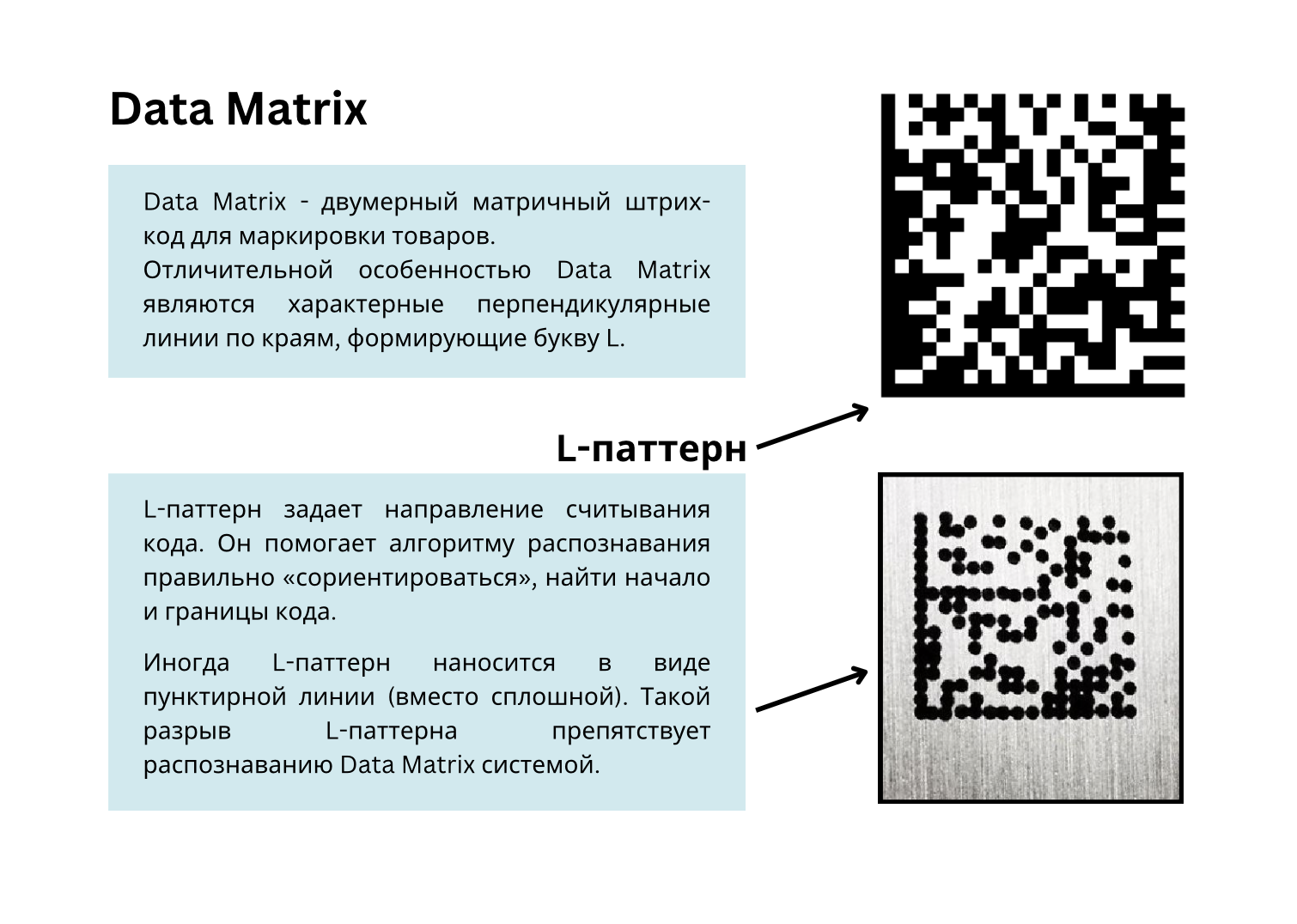
L-паттерн — это характерный угол в виде буквы "L", который есть в Data Matrix. Этот угол образован двумя линиями, которые идут вдоль краёв кода перпендикулярно друг другу. L-паттерн нужен, чтобы алгоритм мог понять, где находятся края кода и как его правильно выровнять перед считыванием.
Однако некоторые производители наносят код с разрывами L-паттера, из-за чего системе сложно определить границы, что приводит к ошибкам при распознавании данных.
У нас несколько подходов к решению этой проблемы:
- Увеличение количества допустимых разрывов в L-паттерне. Этот способ делает алгоритм более гибким и позволяет ему успешно распознавать частично повреждённые L-паттерны.
- Прорисовка вспомогательной линии. Добавление линии в направлении предполагаемого L-паттерна помогает алгоритму обойти разрывы, сохраняя целостность кода.
2. Плохо читаемая синхронизация
Синхронизация — это ключевой элемент для правильного распознавания структуры Data Matrix. Если она плохо читается, то размер оригинальной матрицы может быть определён неправильно. И тогда детекторы либо не распознают матрицу, либо она отбрасывается ещё до декодирования.
В качестве решения мы прибегаем к перебору размеров матрицы. Поскольку размеры матриц заранее известны, можно использовать метод полного перебора для их проверки. Алгоритм последовательно проверяет изображение на соответствие каждой возможной размерности Data Matrix. Например, алгоритм может попробовать распознать матрицу как 10x10, затем как 12x12 и так далее, до тех пор, пока не найдётся подходящий вариант. Этот подход выявляет случаи, когда синхронизация определена неправильно, и повысить вероятность успешного декодирования.
3. "Мусор" в слепой зоне
Иногда внешние элементы изображения могут пересекать угол Data Matrix, создавая «мусор» в зоне вокруг матрицы и тем самым препятствуя нормальному считыванию кода.
Для устранения этой проблемы мы заранее определяем углы матрицы с помощью сторонних методов до того, как изображение будет передано в ZXing, - библиотеку для считывания двумерных кодов. А затем очищаем слепую зону вокруг матрицы, чтобы исключить какие-либо помехи.
4. Искажения Data Matrix
Искажения могут возникать по разным причинам, включая качество печати или неровную поверхность, на которую наклеена Data Matrix. Это частая причина ошибок распознавания кода с мягких упаковок. Искажения часто приводят к тому, что детекторы либо не находят углы, либо не могут определить L-паттерн или синхронизацию. В результате метод SampleGrid также не справляется с коррекцией искажений, так как учитывает только перспективные искажения.
Для борьбы с этой проблемой мы модифицировали функцию SampleGrid. Вместо того чтобы ограничиваться только перспективной коррекцией, был добавлен метод FastVoxelTraversal, учитывающий дополнительные искажения. Его применение с субпиксельной точностью позволило улучшить точность определения углов и учет продольных искажений по осям X и Y при выборке данных.
Заключение
Наша система распознавания маркировки, работающая в режиме реального времени, успешно распознает двумерные коды (Data Matrix, QR-код). Но для обеспечения высокого уровня производительности таких систем крайне важно использовать метрики качества, которые дают объективную оценку работы алгоритмов и помогают быстро выявлять и устранять возможные сбои.
Мы разработали систему подсчета метрик качества работы системы по распознаванию маркировки на товаре, используя Datapipe ETL, которая автоматизирует сбор, обработку и анализ данных. Внедрение подхода, основанного на автоматизированном подсчете метрик качества с помощью MediaPipe и MLFlow, позволяет нашим разработчикам оперативно отслеживать влияние обновлений алгоритмов, оценивать их эффективность и оптимизировать систему для различных типов продукции. Таким образом, мы обеспечиваем стабильную и высокую производительность системы, избегая ошибок, задержек и связанных с ними финансовых потерь.

