

Введение
Одна из самых распространённых задач для AI-ассистента — поиск ответов на вопросы. Пользователи ожидают, что он сможет находить информацию во внутренних wiki, базах знаний техподдержки, Word-документах, Excel-файлах и других корпоративных источниках.
Сегодня такой поиск чаще всего реализуется с помощью подхода Retrieval-Augmented Generation (RAG). Суть проста: сначала ассистент находит фрагменты документов, которые кажутся релевантными запросу, и уже на их основе формирует связанный ответ.
На первый взгляд схема выглядит логичной. Но на практике у классического RAG есть целый ряд ограничений, которые быстро дают о себе знать при реальных внедрениях. В этой статье мы разберём основные проблемы и покажем, как можно их обойти.
Где классический RAG даёт сбой
За последние пару лет мы сделали множество AI-проектов для e-commerce, юридических и медицинских компаний. За это время накопился список типовых ситуаций, в которых классический RAG работает неудовлетворительно. Под классическим RAG мы понимаем наиболее распространённую схему: векторный поиск → top-N релевантных фрагментов → подстановка в контекст LLM. Такой подход опирается только на смысловую близость текста и игнорирует явную структуру данных.
1. Запросы вида «Сколько?» и «Покажи всё»
Обычная ситуация в e-commerce:
— «Покажи все светильники для ванной»
— «Сколько у вас кремов для чувствительной кожи?»
— «Есть ли курсы по программированию с нуля?»
Когда мы ищем это в каталоге, всё просто: фильтруем по полю тип светильника = для ванной, тип кожи = чувствительная или уровень курса = начинающий.
А вот AI-ассистент на классическом RAG чаще всего делает другое:
- он берёт только несколько наиболее «похожих» фрагментов (top-5 или top-10),
- возвращает короткий ответ или часть списка,
- и почти никогда не умеет корректно посчитать общее количество объектов в базе.
Результат: пользователь ждёт полный список или цифру, а получает лишь сэмпл из нескольких элементов.

2. Когда нужен точный факт, а не догадка
Есть целый класс запросов, где «похоже на правду» — это уже ошибка. Пользователь ожидает не вариацию, а конкретное значение. Например:
- «Какой состав у продукта Х?» — здесь нельзя перепутать его с продуктом Y, даже если названия очень похожи.
- «Какая концентрация ингредиента А в продукте Х?» — ассистент должен не только правильно найти нужный продукт, но и вытащить точное число, не выдумывая его.
Классический RAG, работающий только на смысловых совпадениях, в таких случаях часто «угадывает» и выдаёт формулировку, которая выглядит правдоподобно, но не гарантирует корректность. Для бизнеса это превращается в риск: ошибка в цифре или составе может стоить репутации или привести к юридическим последствиям.

3. Вопросы на логику предметной области
Ещё один частый кейс в e-commerce:
— «Какие аксессуары совместимы с этой моделью?»
Классический RAG попытается найти «похожие» тексты и, скорее всего, предложит аксессуары, которые звучат уместно, но на деле не подходят. Например, он может выдать чехол с другим форм-фактором или кабель без нужного разъёма — просто потому, что слова в описании совпали.
Причина в том, что наивный RAG опирается исключительно на семантическую близость текстов. Он не учитывает:
- реальную логику совместимости (Bluetooth-версии, размеры, фирменные коннекторы),
- бизнес-правила («этот аксессуар подходит только к моделям X, но не к Y»),
- связи между сущностями в данных.
В итоге пользователь получает не точный ответ по правилам предметной области, а «догадку», собранную из наиболее похожих фрагментов.

Ограничение языковых моделей: нет модели мира
Все описанные проблемы наивных RAG-подходов упираются в фундаментальную особенность современных языковых моделей: у них нет собственной модели мира, на которую можно было бы опираться при рассуждениях.
LLM не строят внутреннюю «онтологию» предметной области — для них факты и связи не отделены от статистики текста, на которой они обучены. Поэтому, отвечая на вопросы, модель не «думает», а имитирует рассуждение, подбирая наиболее правдоподобные комбинации слов, опираясь на примеры из тренировочных данных.
Отсутствие явной ментальной модели ведёт к предсказуемым ограничениям:
- Слабое обобщение в ситуациях, которых не было в обучении.
- Склонность к противоречиям на длинных логических цепочках.
- Неспособность «проигрывать» систему в голове (например, смоделировать эксперимент или бизнес-процесс).
- Игнорирование устойчивых правил и инвариантов, если они не зашиты явно в данных.
Для областей, где критична строгая логика и точность — инженерные расчёты, научные исследования, юридические и финансовые процессы — это становится принципиальным ограничением.
Наша гипотеза
Мы исходим из простой идеи: модель предметной области создаётся человеком и хранится вне LLM.
Эта модель подаётся ассистенту как контекст рассуждений. В такой архитектуре LLM перестаёт быть «носителем знаний» и становится интерфейсом, который понимает вопросы и переводит их в корректные действия по дата-модели.
Мы предлагаем изменить подход к RAG. Вместо опоры только на семантическое сходство текста мы:
- объясняем ассистенту структуру домена: сущности, их атрибуты и связи;
- даём инструменты извлечения данных — помимо векторного поиска, структурированные запросы (SQL/Cypher) и вызовы API;
- даём методичку (playbook) — как выбирать инструменты и строить логику ответа под разные типы запросов.
Такой «Semantic RAG» сочетает гибкость языковой модели и точность формальной структуры.
Наш подход: Semantic RAG
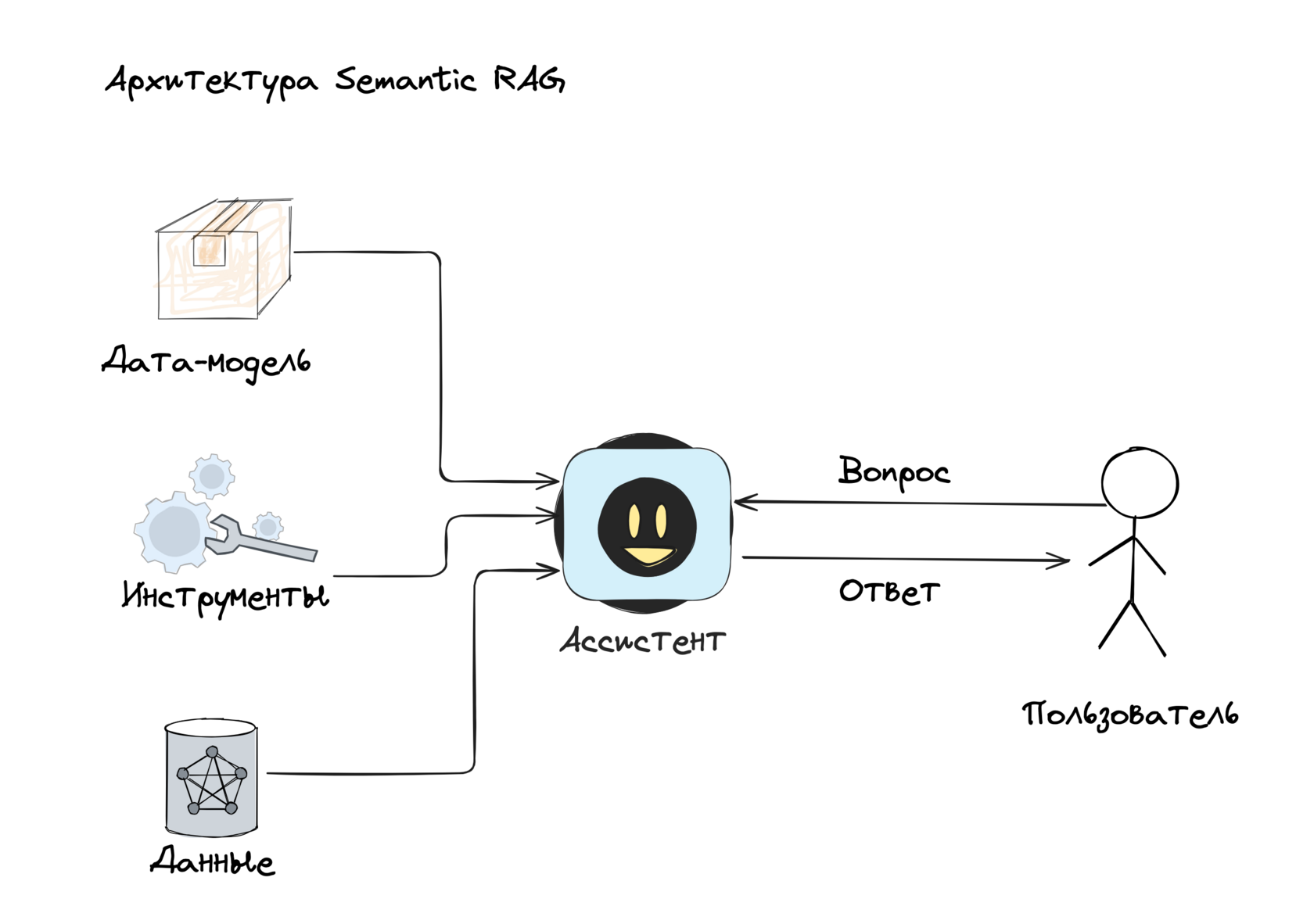
Из этой гипотезы рождается архитектура Semantic RAG.
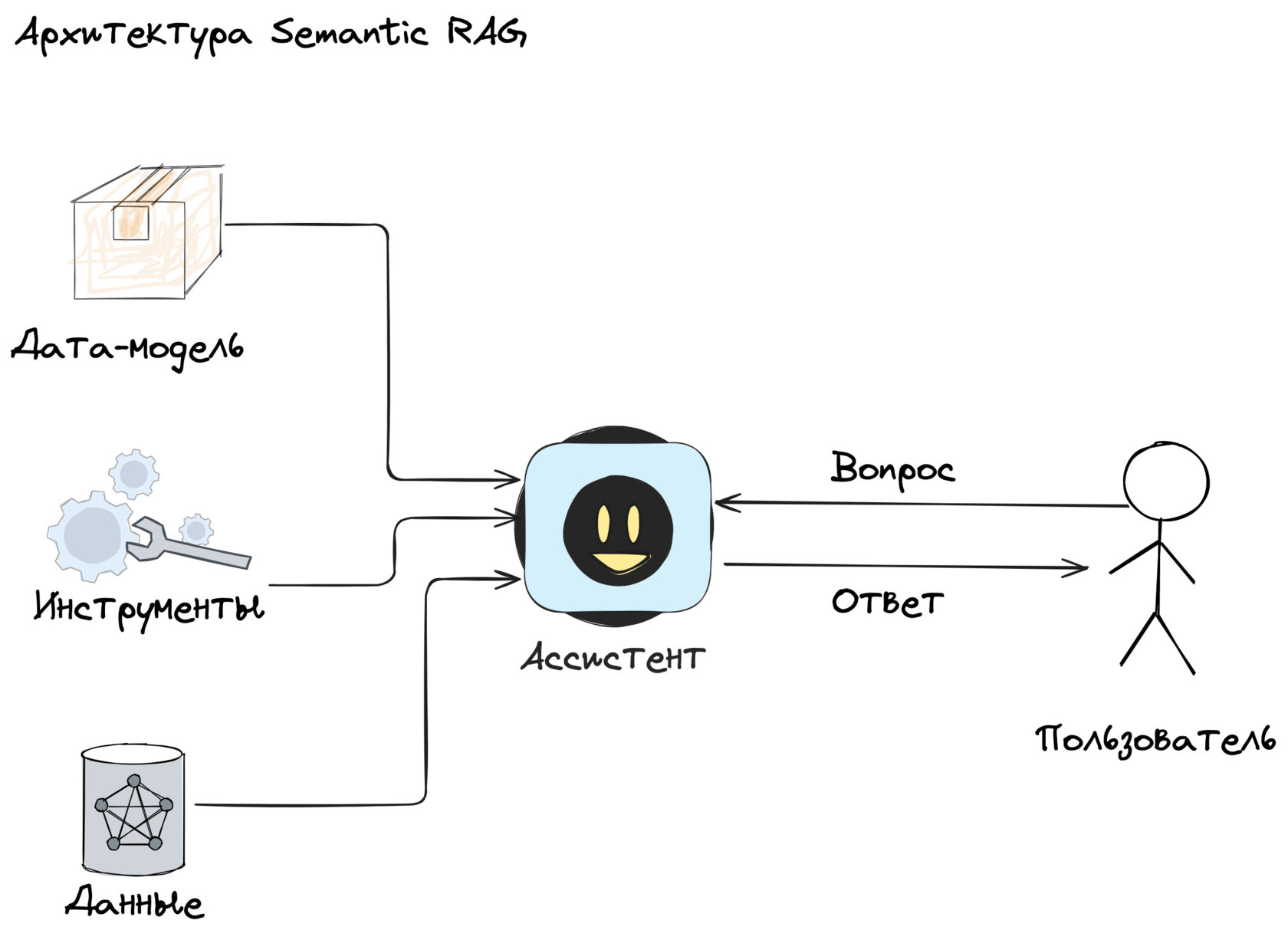
Ассистент сверяется с дата-моделью и определяет, какие сущности, атрибуты и связи нужны для ответа.
Ассистент строит план и использует инструменты:
Найденные факты собираются в контекст ответа с чёткими ссылками на источники: doc_id:chunk_id, row_id в базе, идентификаторы API-ответов.
Затем ассистент формулирует ответ, указывая источники.
Ассистент строит план и использует инструменты:
- семантический (векторный) поиск по документам;
- структурированные запросы к базе (SQL/Cypher);
- вызовы внешних API.
Найденные факты собираются в контекст ответа с чёткими ссылками на источники: doc_id:chunk_id, row_id в базе, идентификаторы API-ответов.
Затем ассистент формулирует ответ, указывая источники.
Далее разберём, как это устроено в деталях.
Предметная область для нашего примера
Чтобы дальше было понятно, на чём основан Semantic RAG, возьмём упрощённый пример из юридического домена.
Контекст: мы работаем с производителями, которым для вывода продукции на рынок нужны документальные подтверждения соответствия законодательству (сертификаты качества/соответствия и т.д.).
Какие вопросы должен закрывать ассистент:
Общие по законодательству и практике:
— «Что такое сертификат качества?»
— «Когда требуется сертификат соответствия?»
— «Что такое сертификат качества?»
— «Когда требуется сертификат соответствия?»
Точные, структурные:
— «Если я произвожу <конкретную продукцию>, какой ей соответствует CN-код (Combined Nomenclature)?»
— «Для CN-кода X какие документы обязан получить производитель?»
— «Если я произвожу <конкретную продукцию>, какой ей соответствует CN-код (Combined Nomenclature)?»
— «Для CN-кода X какие документы обязан получить производитель?»
Из чего собираем базу знаний:
- Нормативные акты — индексируем «как есть», без правок.
- FAQ/разборы практики — экспертные ответы с примерами применения норм.
- Справочник CN-кодов — перечень кодов и наименований продукции.
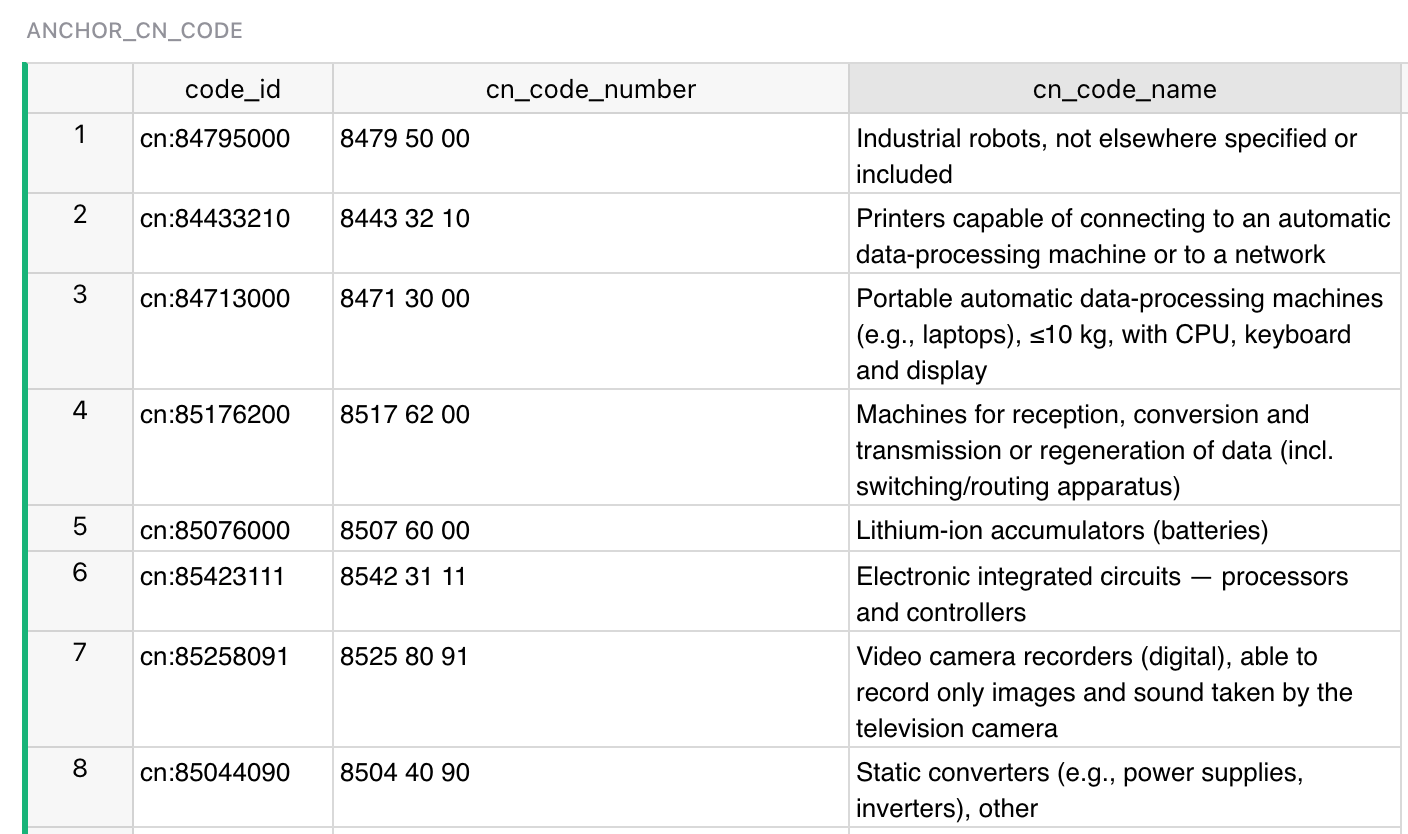
- Справочник подтверждающих документов — все типы сертификатов/деклараций, которые могут требоваться.
- Таблица соответствий (CN → документы) — дистиллированное экспертное знание: к каким CN-кодам какие документы применяются, с условиями. Эта логика извлекается по правилам из множества нормативных актов, но мы не перекладываем реконструкцию правил на LLM — готовим таблицу заранее и загружаем её как часть структуры.
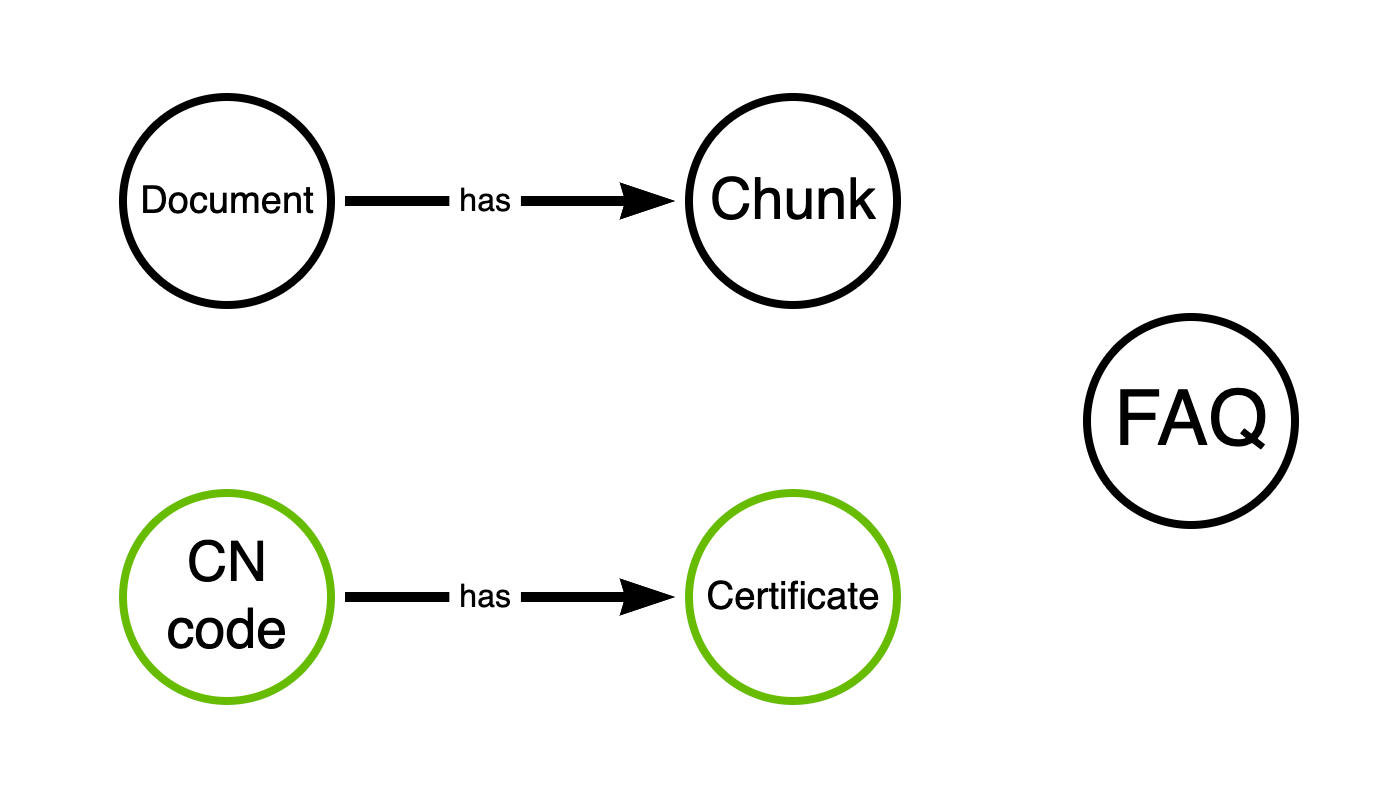
Чтобы было нагляднее, соберём всё в единую картинку:
Данные
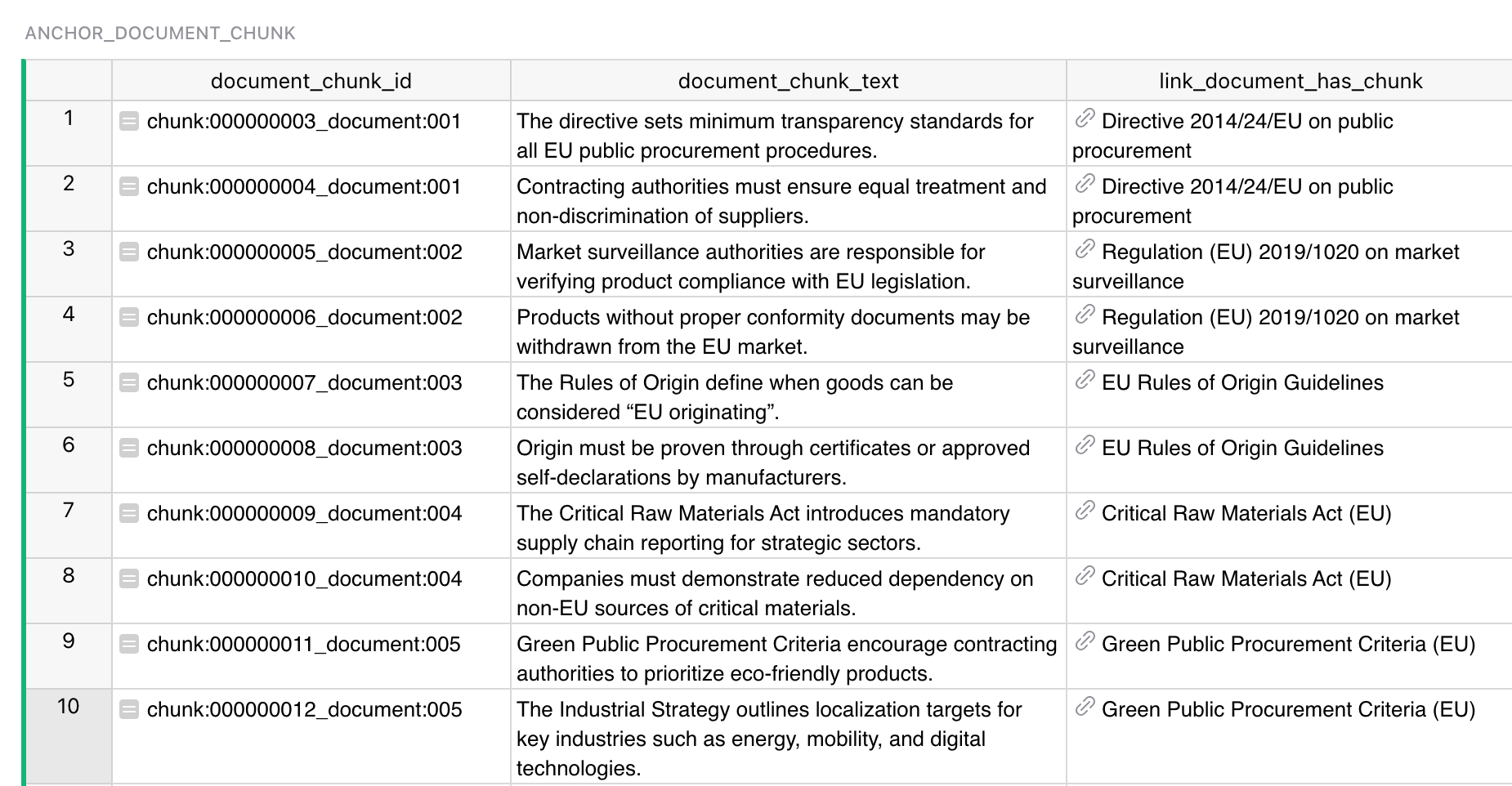
Ниже — минимальный набор таблиц, на которых держится наш кейс (скриншоты — структура/пример данных).
Document
- Нормативные акты и официальные письма.

Document Chunk
- Нарезанные фрагменты документов для семантического поиска.
FAQ
- Вопросы и экспертные ответы из практики (саппорт/кейсы).

CN code
- Справочник кодов и наименований продукции (Combined Nomenclature).
Compliance document
- Перечень видов подтверждающих документов (сертификаты/декларации).
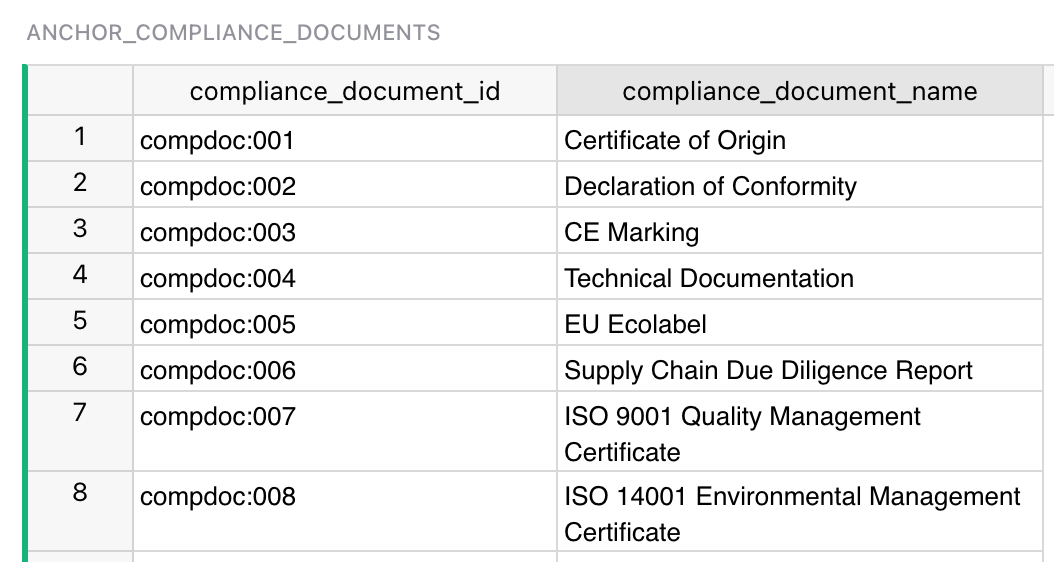
И таблица-связка между CN code и Compliance document (для конкретного товара по коду нужны конкретные документы). Эту связку мы реализуем отдельной link table для удобства.
Дата-модель
Для описания данных мы используем подход, который называется Минимальное моделирование. Мы начали использовать его несколько лет назад для работы над аналитическими проектами, и этот подход идеально перекладывается на работу с LLM.
Для того, чтобы замоделировать любой домен, нам надо выделить в данных:
- Анкеры – это существительные (например, пользователь, заказ, товар, склад итп)
- Атрибуты – это свойства анкеров (например, у пользователя есть емейл, у товара есть название)
- Линки – связи между анкерами (например, пользователь оформил заказ).
Таблица Анкеров:
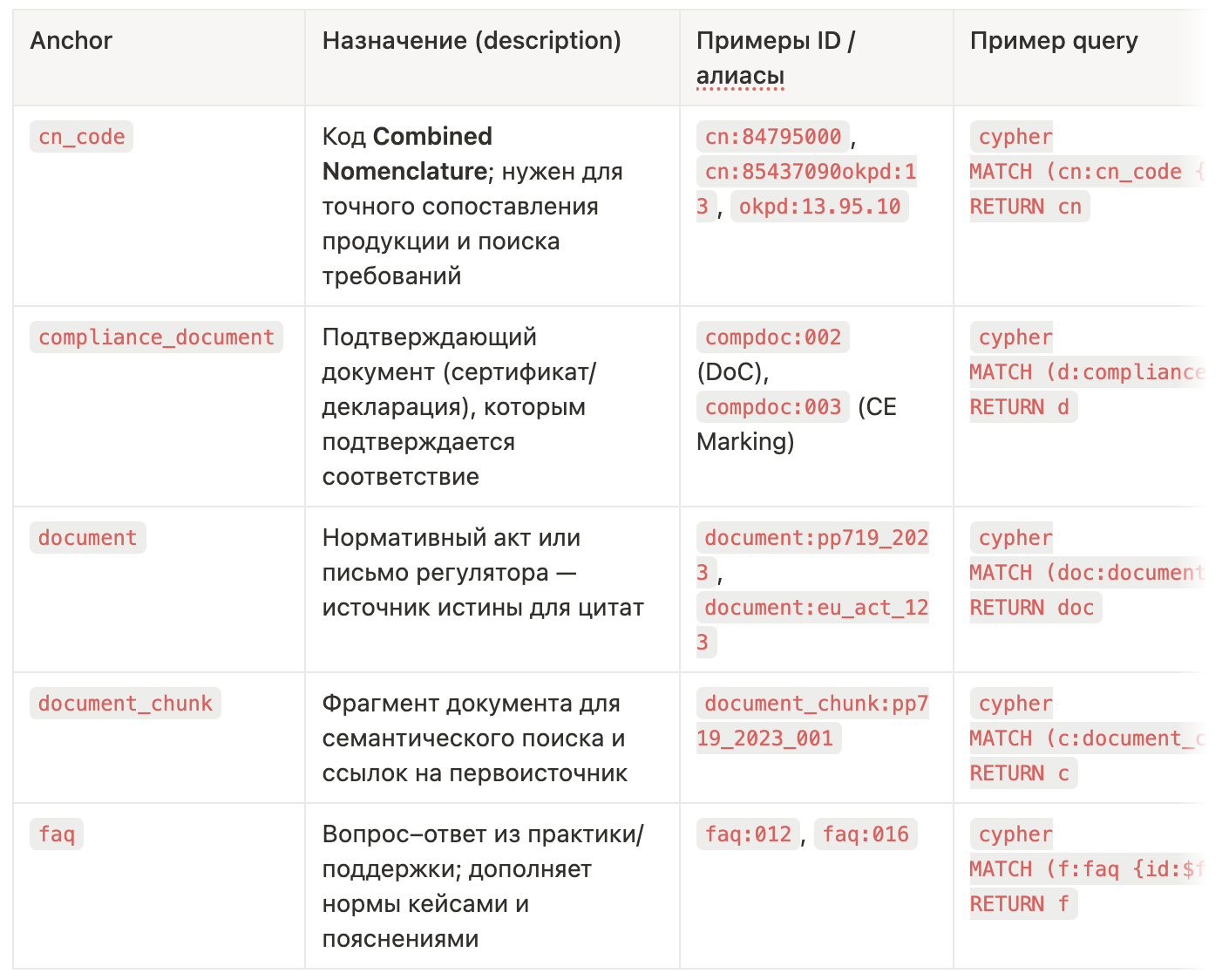
Таблица Атрибутов:
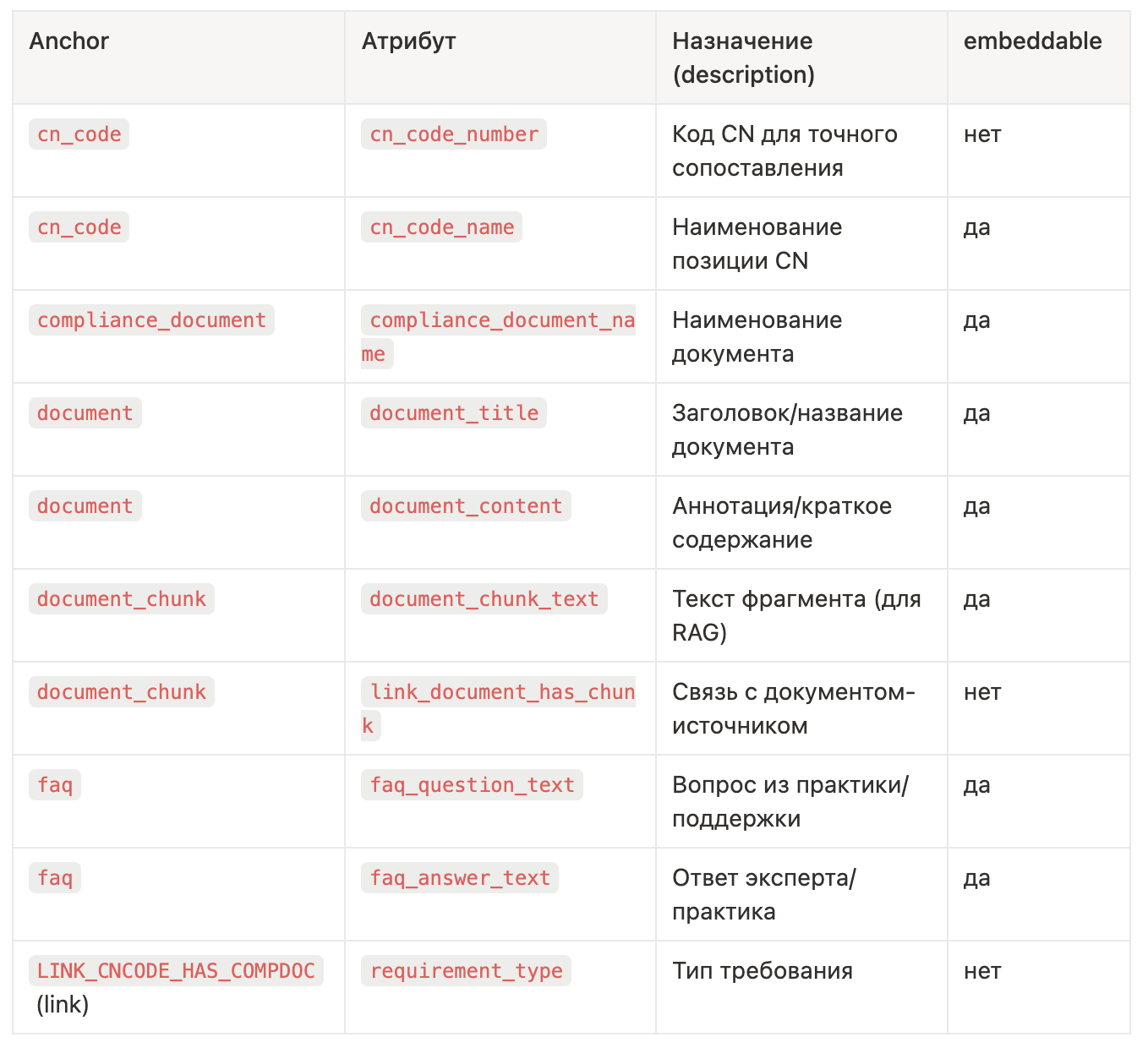
Таблица Линков:
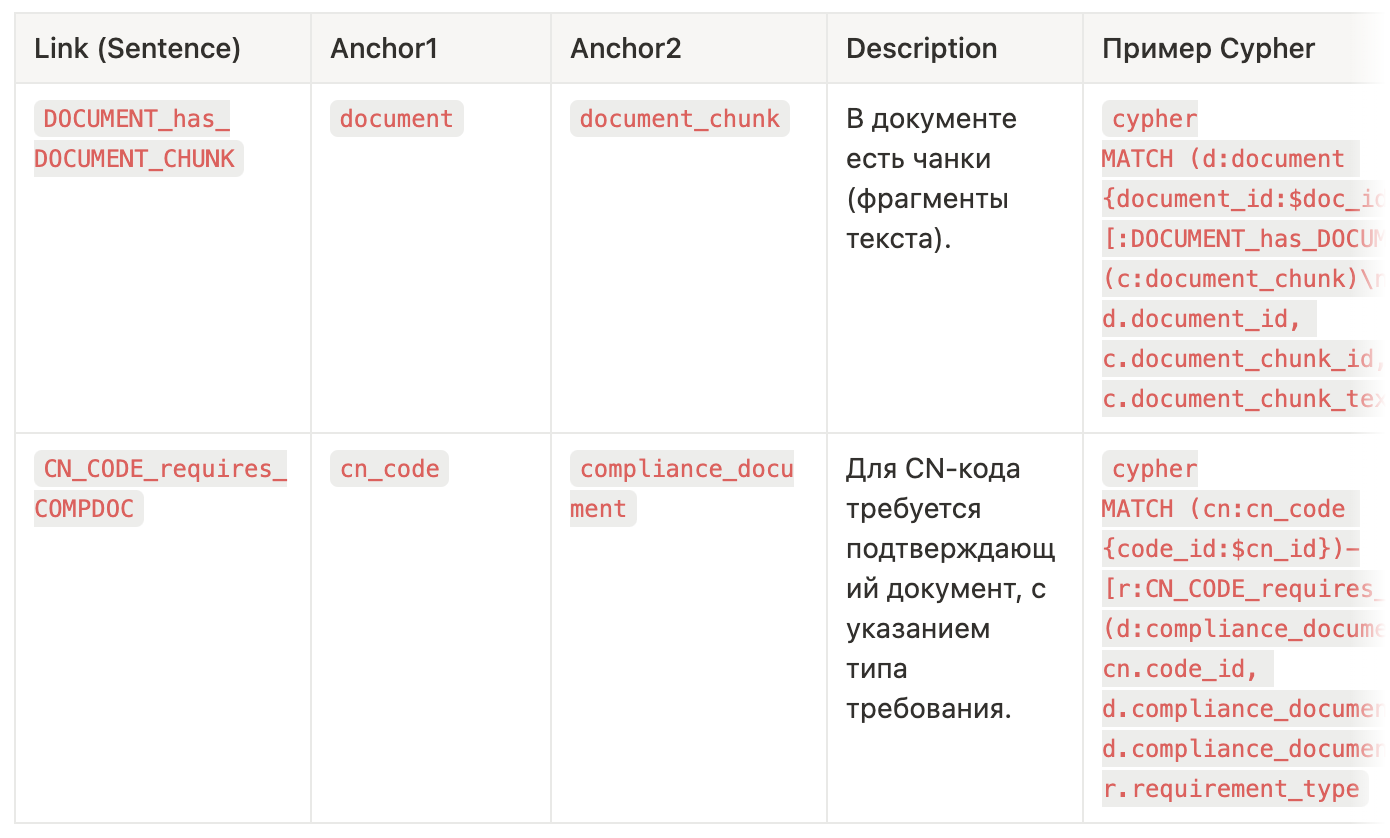
Описание анкеров, атрибутов и линков – это простые таблички, которые в виде текста передаются в контекст ассистента вместе с запросом пользователя.
Чтобы ассистент корректно планировал шаги и выбирал нужные данные/инструменты, для каждого анкера, атрибута и линка мы задаём несколько служебных полей:
description — описание
Кратко и однозначно объясняет, когда и зачем использовать сущность/поле/связь.
Именно по этому описанию LLM решает, брать ли объект в работу, и как интерпретировать результат.
query_example — пример запроса
Показательный запрос, который извлекает нужные данные:
— SQL (если храним в реляционной БД),
— Cypher (если граф, напр. Memgraph/Neo4j),
— либо пример вызова API (если данные приходят «по требованию»).
Примеры работают как few-shot для инструментов: снижают число ошибок в синтаксисе и параметрах.
embeddable — признак векторного поиска (true/false)
Указываем, нужно ли строить эмбеддинги и искать по смыслу.
Не включаем для числовых полей, идентификаторов, кодов с точным сопоставлением (например, CN-код).
Включаем для длинных текстов (фрагменты норм, ответы из FAQ), а также для «названий/описаний», по которым нужен «семантический» поиск.
Кратко и однозначно объясняет, когда и зачем использовать сущность/поле/связь.
Именно по этому описанию LLM решает, брать ли объект в работу, и как интерпретировать результат.
query_example — пример запроса
Показательный запрос, который извлекает нужные данные:
— SQL (если храним в реляционной БД),
— Cypher (если граф, напр. Memgraph/Neo4j),
— либо пример вызова API (если данные приходят «по требованию»).
Примеры работают как few-shot для инструментов: снижают число ошибок в синтаксисе и параметрах.
embeddable — признак векторного поиска (true/false)
Указываем, нужно ли строить эмбеддинги и искать по смыслу.
Не включаем для числовых полей, идентификаторов, кодов с точным сопоставлением (например, CN-код).
Включаем для длинных текстов (фрагменты норм, ответы из FAQ), а также для «названий/описаний», по которым нужен «семантический» поиск.
Инструменты: как ассистент получает данные
Когда данные подготовлены, а дата-модель описана, остаётся дать ассистенту инструменты для извлечения фактов. Мы используем три класса инструментов.
1. Векторный поиск
Классика RAG, но со указанием скоупа: мы явно указываем, по каким анкерам/атрибутам искать (только тем, где embeddable=true). Это снижает шум и улучшает точность ответа.
Сигнатура (упрощённо):
Сигнатура (упрощённо):
vts(query, anchor, label, k=8, min_score=0.3, filters={})Примеры вызовов:
vts(anchor="faq", label="faq_question_text", query=$q)
vts(anchor="document_chunk", label="document_chunk_text", query=$q)2. Структурированные запросы (Cypher/SQL)
Для точных операций («Сколько?», «Покажи всё», совместимость, фильтры по условиям/датам) ассистент исполняет структурированные запросы. В нашей реализации данные лежат в Memgraph, поэтому используем Cypher (аналогично работает и с SQL).
Пример (какие документы требуются для CN-кода, с указанием типа):
MATCH (cn:cn_code {cn_code_id: "cn:84795000"}) -[rel:CN_CODE_requires_COMPDOC]->(d:compliance_document)
RETURN
d.compliance_document_id AS compdoc_id,
d.compliance_document_name AS compdoc_name,
rel.requirement_type AS requirement_type3. Библиотека инструментов (расширяемая)
Библиотека инструментов может расширяться в зависимости от задач – можно дать ассистенту инструменты обращения в API (внутренние и внешние), инструменты веб-поиска и прочее.
Playbook: как ассистент рассуждает
Когда у нас есть подготовленные данные и описанная дата-модель, мы учим ассистента правильной последовательности шагов под разные типы запросов.
Например, для нашего юридического домена мы можем записать две инструкции:
Если задан вопрос про законодательство:
Например, для нашего юридического домена мы можем записать две инструкции:
Если задан вопрос про законодательство:
- сначала выполни векторный поиск по document_chunk_text (поскольку там описана юридическая практика)
- затем по faq (поскольку там уточнения)
- дай ответ в виде: “по законодательству так, на практике иначе”
Если задан вопрос про сертификационные документы для продукции
- сначала воспользуйся векторным поиском и пойми CN-код продукции
- затем выполни структурированный запрос по базе: по коду продукции найди сетификационные документы
Вот так выглядит соответствующая инструкция в Playbook:

Как ассистент выбирает инструменты
Перед финальным ответом ассистент проходит несколько итераций извлечения фактов, комбинируя инструменты в зависимости от типа запроса и дата-модели.
Например, на первой итерации ассистент может поискать запрос по законодательно базе и FAQ. На второй – найти конкретный CN-код запрашиваемой продукции. На третьей – по CN-коду найти связанные документы и собрать из этого общий ответ.
Пример промпта (шаблон для планировщика инструментов):

Посмотрим, как ассистент отвечает на разные типы вопросов на демо-данных (коды/названия условны).
Вопрос пользователя:
Какая документация нужна для вывода промышленных роботов на рынок ЕС?
Этот вопрос явно относится к категории "сертификационные документы по продукции".
Посмотрим, как рассуждает ассистент.
Шаг 1. Поиск кандидатов на CN-код Ассистент начинает с векторного поиска по справочнику CN Code, чтобы понять, какой код соответствует описанию «промышленные роботы».
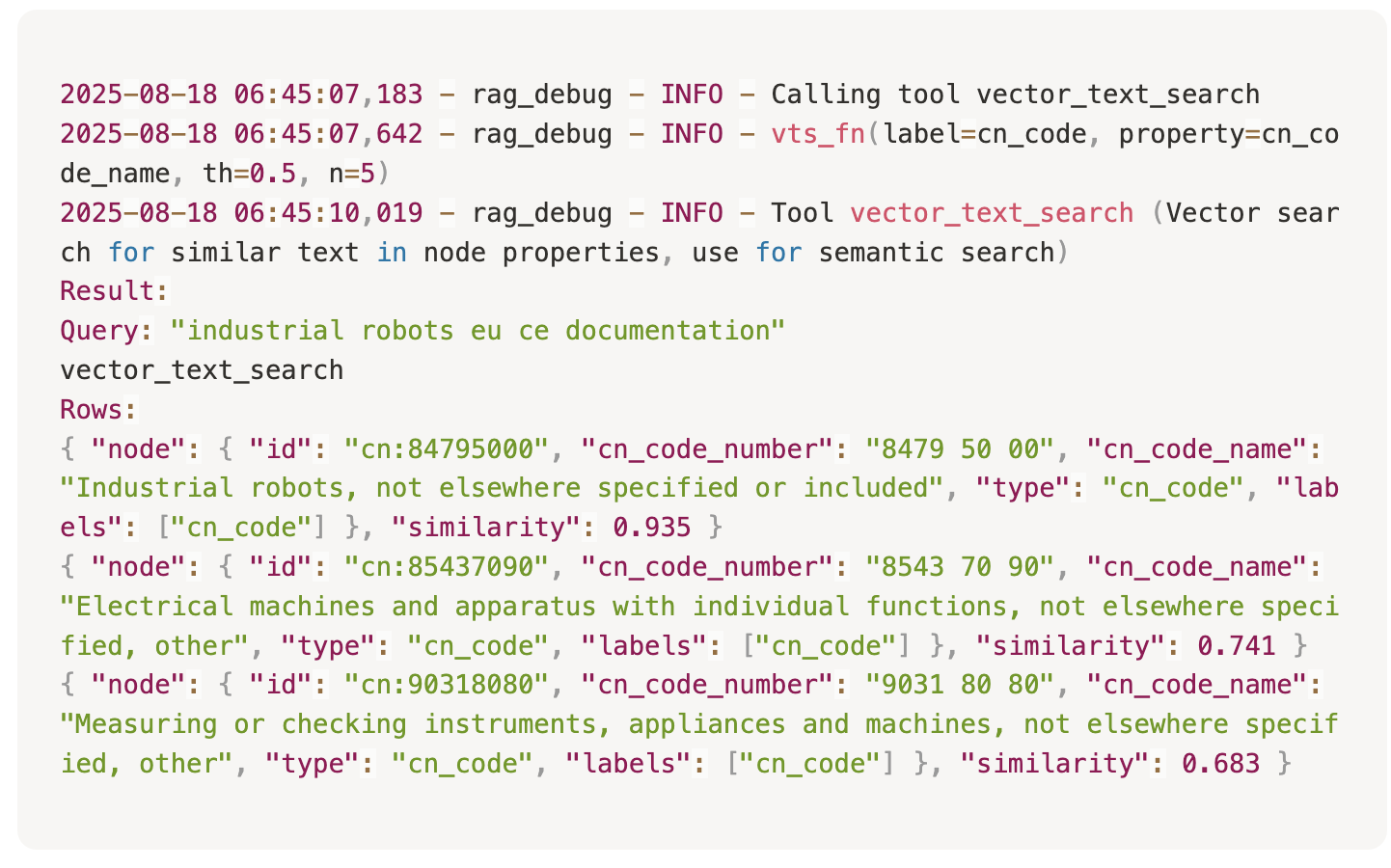
На выходе ассистент получает трёх кандидатов:
- 8479 50 00 — Industrial robots, not elsewhere specified or included (релевантный)
- 8543 70 90 — Electrical machines and apparatus with individual functions, not elsewhere specified, other
- 9031 80 80 — Measuring or checking instruments, appliances and machines, not elsewhere specified, other
Очевидно, что основной кандидат — 8479 50 00 (промышленные роботы). Но на этом этапе ассистент не обязан жёстко выбирать один код: он может оставить несколько ближайших результатов в контексте, чтобы позже уточнить через дополнительные шаги или запросить уточнение у пользователя, если уверенность недостаточно высока.
Шаг 2. Структурированный запрос по CN-коду На втором шаге ассистент следует Playbook: после того как найден CN-код, он делает структурированный запрос к графовой базе.
Цель — по коду продукции получить список связанных документов и тип требований (обязательные, условные, опциональные).

Шаг 3. Дополнение практикой из FAQ После структурного запроса ассистент добавляет к ответу практические нюансы, которые часто выходят за рамки сухих нормативов. Для этого он выполняет векторный поиск по базе FAQ.

Результат:
Ассистент находит пять релевантных ответов из практики закупок. Они дополняют нормативные требования конкретикой.
Таким образом, ассистент не только даёт перечень обязательных документов (шаг 2), но и добавляет «как это работает на тендерах» — то, чего в законах напрямую нет, но без чего бизнес-ответ был бы неполным.
Шаг 4. Формирование финального ответа
На этом этапе у ассистента уже есть достаточно фактов:
— выдержки из нормативных документов,
— список связанных сертификатов для CN-кода,
— практические разъяснения из FAQ.
Теперь он собирает всё это в человекочитаемый, но проверяемый ответ.

Что здесь важно
- Ассистент вернул полный список документов, а не случайный сэмпл.
- В ответе есть ссылки на конкретные ID (compdoc:…, faq:…), поэтому результат можно проверить и воспроизвести.
- Ответ собран из структурированных данных и реальных документов, а не «придуман» LLM. Это резко снижает риск галлюцинаций.
- Исправляемость встроена в процесс: если чего-то не хватает или есть ошибка, понятно, что нужно поправить — добавить документ в базу или уточнить связь, а не «ловить» модель на вымыслах.
Техника
Теперь — о том, как устроена архитектура с точки зрения данных и инфраструктуры.
Графовая vs реляционная БД (Cypher vs SQL)
На старте мы решали, какую базу выбрать для ассистента:
- реляционную (PostgreSQL + SQL),
- или графовую (Neo4j / Memgraph + Cypher).
Мы остановились на графовой базе, и вот почему:
Гибкость схемы
База знаний в реальных проектах постоянно расширяется.
Сегодня у нас есть «CN-коды» и «сертификаты», завтра эксперт добавляет новый справочник совместимости или новое поле «примечания».
В графовой БД такие изменения вносятся легко: добавил новую колонку или связь — и ассистент сразу это «увидел».
В реляционных БД изменения схемы вносить гораздо сложнее.
Удобство языка запросов
Cypher короче и нагляднее для работы со связями: запросы выглядят как схема.
В SQL те же операции превращаются в каскады JOIN, которые хуже читаются и сложнее генерируются LLM.
Устойчивость к «дрейфу» модели
Если LLM ошиблась в имени свойства или связи, Cypher вернёт просто пустой результат.
В SQL обращение к несуществующему столбцу сломает весь запрос.
Для ассистента, который пишет код «на лету», это важно: графовая БД прощает ошибки генерации.
База знаний в реальных проектах постоянно расширяется.
Сегодня у нас есть «CN-коды» и «сертификаты», завтра эксперт добавляет новый справочник совместимости или новое поле «примечания».
В графовой БД такие изменения вносятся легко: добавил новую колонку или связь — и ассистент сразу это «увидел».
В реляционных БД изменения схемы вносить гораздо сложнее.
Удобство языка запросов
Cypher короче и нагляднее для работы со связями: запросы выглядят как схема.
В SQL те же операции превращаются в каскады JOIN, которые хуже читаются и сложнее генерируются LLM.
Устойчивость к «дрейфу» модели
Если LLM ошиблась в имени свойства или связи, Cypher вернёт просто пустой результат.
В SQL обращение к несуществующему столбцу сломает весь запрос.
Для ассистента, который пишет код «на лету», это важно: графовая БД прощает ошибки генерации.
После этого мы выбирали конкретный движок. Основные кандидаты — Neo4j Community и Memgraph Community.
Наш ключевой критерий был прост: нам нужно масштабироваться по чтению, не переходя сразу на платную Enterprise-лицензию.
У Memgraph Community это доступно «из коробки» за счёт топологии один мастер + несколько read-replica.
У Neo4j Community такого нет — работает только в single-instance, и единственный способ расти по нагрузке — усиливать один сервер (вертикально). Горизонтального масштабирования без Enterprise-версии нет.
Memgraph хранит граф в памяти, поэтому ресурсы сервера нужно планировать с запасом.
При этом главный «потребитель» памяти в нашей архитектуре — не сам граф (его структура обычно лёгкая), а векторные эмбеддинги, которые мы добавляем для семантического поиска.
В реальных проектах это означает: закладывать 4–16 ГБ RAM и следить за ростом базы эмбеддингов.
Если граф не помещается в память, есть так называемый Transactional режим, когда Memgraph сохраняет граф на диске, но он экспериментальный: медленнее; всё, что участвует в транзакции, всё равно должно помещаться в RAM.
Еще одно ограничение как Memgraph, так и Neo4j – это отсутствие multi tenancy, то есть один проект – одни самостоятельный инстанс Memgraph.
Несмотря на требовательность к ресурсам, приятные особенности Memgraph перевесили, и мы выбрали его для дальнейшей работы.
Структурированные ручные данные
Для управления справочниками и таблицами мы используем Grist.
- У Grist интерфейс, привычный бизнес-пользователям — напоминает Excel, но поддерживает формулы, связи и более гибкую модель данных.
- Данные легко обновлять: эксперт может добавить колонку или новое поле без участия разработчиков.
- Экспорт происходит в формате SQLite, что упрощает загрузку в графовую базу и делает процесс похожим на полноценный ETL-пайплайн.
Векторное хранилище
Для поиска по текстовым фрагментам (нормативные документы, ответы FAQ) мы используем vector store внутри Memgraph.
Общий процесс работы системы
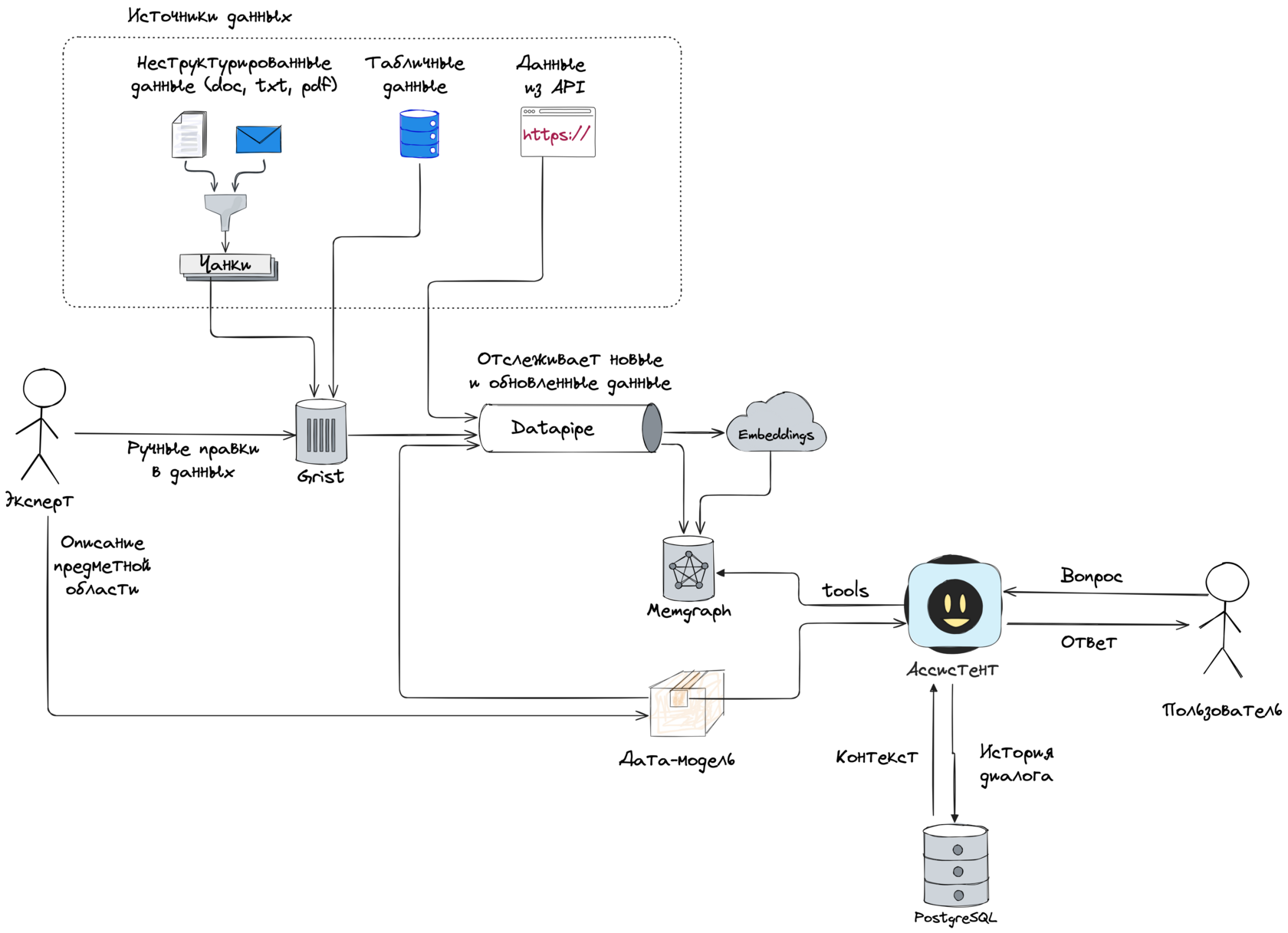
Вот как устроена система — простыми словами.
Источники данных
- Документы (doc/pdf/txt) → нарезаем на чанки, храним в Grist для просмотра и правок.
- Справочники и таблицы → тоже в Grist, без особых модификаций.
- API-данные (часто меняются, их много) → грузим сразу в Memgraph.
Эмбеддинги и загрузка данных в Memgraph
Чтобы использовать векторный поиск, каждому фрагменту данных нужен эмбеддинг. Это затратная операция, поэтому:
- Эмбеддинг считается ровно один раз — при добавлении или изменении записи.
- Для отслеживания изменений мы используем фреймворк Datapipe.
- Datapipe автоматически отслеживает, какие записи изменились, и отправляет на пересчёт только новые или изменённые записи.
Работа эксперта
Система остаётся точной только если в цикле есть эксперт. Его задачи:
- Описать дата-модель в терминах Анкеров (сущностей), Атрибутов и Линков.
- Составить Playbook — инструкции, по каким шагам ассистент должен отвечать на типовые вопросы (какие данные смотреть, какие выводы делать).
- Внести ручные правки в данные, если автоматическая загрузка дала шум или пропуски.
Работа ассистента
Финальный шаг — взаимодействие ассистента с пользователем:
Ассистент получает:
- вопрос пользователя,
- описание дата-модели,
- Playbook (рецепты рассуждений),
- доступ к данным и инструментам.
Дальше он сам решает, какие инструменты применить:
- поиск по эмбеддингам,
- структурированный запрос в Memgraph,
- вызовы API для актуального контекста.
И формирует ответ с указанием источников, чтобы его можно было проверить и воспроизвести.
Вся история и контекст диалогов сохраняется в PostgreSQL.
Как проверять качество ответов ассистента
Качество ассистента невозможно оценивать «на глаз» — нужен системный процесс тестирования. Для этого мы используем золотой датасет (golden dataset) — набор типовых вопросов с эталонными ответами.
1. Формирование золотого датасета
Для каждого сценария из Playbook готовим 20–30 примеров вопросов.
Примеры должны охватывать все ветки логики: разные форматы запросов, краевые кейсы, исключения.
Для каждого эталонного ответа фиксируем ID чанков и структурных данных, на которых он должен базироваться.
Так мы учитываем, что текст LLM может перефразировать ответ, но источники остаются неизменными.
2. Когда запускать тесты
Тесты прогоняются после каждого серьёзного изменения:
- обновление или расширение данных,
- изменения в дата-модели (новые анкеры/связи),
- смена или обновление LLM.
3. Метрика качества
В качестве основной метрики используем Accuracy — долю полностью корректных ответов (и по содержанию, и по источникам).
Польза подхода
Клиенты часто спрашивают: «А какое качество ответов у ассистента?»
Правильный ответ: зависит от того, в какой зоне работает запрос.
1. Неструктурированные тексты (чанки)
- Ответы строятся только на семантическом поиске по фрагментам.
- Качество зависит от множества факторов: полноты источников, политики чанкования, качества ретривера и того, как именно пользователь сформулировал вопрос.
- Плюсы: быстрый запуск, возможность покрыть «серую зону» знаний без моделирования.
- Минусы: пропуски фактов, дубли, неоднозначности; сложнее писать тесты и проверять корректность правил.
- Практика показывает: точность держится в районе 60–70%.
2. Структурированные данные (дата-модель + логика)
- Основа: граф с чёткими сущностями, атрибутами и связями.
- Поверх графа задаётся Playbook с логикой рассуждений и проверок.
- Преимущества:
- контролируем, откуда берётся факт и как он вычисляется;
- результаты предсказуемы, повторяемы и отлаживаемы.
- Результат: качество ответов выходит на уровень 90–97%, в зависимости от сложности предметной области и полноты модели.
Вывод
Классический RAG, основанный только на векторном поиске, удобен как быстрый способ «подключить ассистента к документам». Но он неизбежно упирается в ограничения:
- не умеет показать полный список объектов,
- не гарантирует фактической точности,
- слабо справляется с логикой предметной области.
Причина в природе LLM: у модели нет устойчивой «карты мира», и без внешней структуры она склонна к неточностям и галлюцинациям.
Semantic RAG решает эти проблемы.
Мы явно задаём модель предметной области (анкеры, атрибуты, линки), подключаем структурированные источники и даём ассистенту набор инструментов — от векторного поиска до Cypher-запросов и API. В такой схеме LLM выступает не «хранилищем знаний», а интерфейсом для работы с базой.
Что это даёт
- Полные и проверяемые ответы — с указанием источников и ID записей.
- Соблюдение правил и ограничений домена, а не их имитацию.
- Масштабируемость: возможность расширять данные и увеличивать нагрузку без ломки схемы.
- Автоматическую проверку качества — через golden dataset и автотесты.
- Точность структурированных ответов на уровне 90–97%, чего недостижимо для «чистого» чанк-RAG.
Итог: Semantic RAG сочетает сильные стороны LLM и структурированных баз. Это система, которая даёт объяснимые, воспроизводимые и практически полезные ответы, на которые бизнес действительно может опереться.

