


Задача
Зачем нужна классификация товаров на полках в ритейле?
Допустим, вы - большая сеть супермаркетов. Вы знаете, какие товары приходят к вам на склад. По чекам понимаете, сколько было продано каждого товара. По камерам под потолком можете примерно понять, сколько людей посещают в магазин и где они обычно ходят. Но вы, скорее всего, мало что ведаете о том, что происходит на самих полках:
- Есть ли кола на полке с напитками?
- Может быть уже разобрали акционные мандарины?
- Или может кто-то перед кассой передумал и поставил бутылку пива на полку с детскими игрушками?
Если бы вы точнее знали, что происходит на полках, можно было бы прицельно вызывать сотрудника магазина для исправления таких проблем, а не ждать, пока сотрудник при обходе сам всё это заметит. Кроме того, можно повышать доступность товара на полке (On-Shelf Availability, OSA), что в теории может повысить выручку, так как больше товаров будет в наличии, и покупатель всегда найдет то, что ищет (или совершит импульсную покупку).
Классификация в нашем случае: масштабы, цели, сложности
Мы работали с двумя сетями супермаркетов. Пилот проводили в одном небольшом супермаркете «у дома», а затем масштабировались на два флагманских супермаркета известной сети.
Цель была простая – распознавать все товары на всех полках, а дальше уже по запросам заказчика строить какую-то downstream-аналитику, создавать «операции» по выносу товаров со склада и так далее. Но сейчас будем говорить именно про распознавание товаров на полках. Сложностей было много, но в этом и весь интерес, так что пройдёмся по некоторым из них.
Цель была простая – распознавать все товары на всех полках, а дальше уже по запросам заказчика строить какую-то downstream-аналитику, создавать «операции» по выносу товаров со склада и так далее. Но сейчас будем говорить именно про распознавание товаров на полках. Сложностей было много, но в этом и весь интерес, так что пройдёмся по некоторым из них.
- Для начала нужно установить камеры и разработать инфраструктуру, чтобы они раз в полчаса делали снимки и передавали их куда надо.
- В разных отделах магазинов освещение очень отличается. Возникает проблема: фотографии с камер выглядят совершенно по-разному. Доходит до того, что одни и те же товары на разных полках (например, кола в холодильнике и кола на акционном стеллаже) выглядят совершенно иначе.
- Классическая проблема холодного старта (cold start) - что делать, когда запускаемся в новом магазине?
- Постоянное пополнение ассортимента и перестановки на полках, которые от нас не зависят и нами не контролируются.
И много других проблем. Про некоторые из них мы поговорим в цикле статей про классификацию, про другие (больше связанные с железом) напишут мои коллеги.
Данные и разметка
Данные
Камеры установили, инфраструктуру настроили, – теперь мы имеем N камер. С каждой камеры снимки делаются каждые полчаса и сразу же попадают в S3.
Несколько примеров того, какие могут быть снимки с камер:
Несколько примеров того, какие могут быть снимки с камер:

Стандартный снимок, на котором все хорошо видно

Перспективные искажения + засветы (черные края по бокам - это уже другие стеллажи, они тут просто замазаны)

Маленькие и похожие друг на друга товары. Не смог прочитать текст на упаковке - проиграл.

Препятствия в виде дверей холодильников и бликов на стеклах
Снимки с камер необходимо для начала отфильтровать, поскольку там попадаются люди, тележки, коробки и прочие препятствия, но обнаружение препятствий - это тема отдельной статьи.
Далее для каждого фото с камеры мы можем прогнать детектор, чтобы достать оттуда все товары. В нашем случае это довольно стандартный свежий YOLO, на котором можно подробно не останавливаться. Но после него мы наконец имеем данные, которые нужны для классификации: вырезанные по координатам детекций кропы с каждого фото и с каждой камеры.
Далее для каждого фото с камеры мы можем прогнать детектор, чтобы достать оттуда все товары. В нашем случае это довольно стандартный свежий YOLO, на котором можно подробно не останавливаться. Но после него мы наконец имеем данные, которые нужны для классификации: вырезанные по координатам детекций кропы с каждого фото и с каждой камеры.
Разметка
К сожалению, нет в мире моделей, которые могли бы с ходу сказать, какой на фото товар, даже имея под рукой весь каталог (на 20+ тысяч товаров). Поэтому нам, конечно же, понадобится человеческая разметка, а вообще можно просто нанять 1000 индусов.
Разметку начинали делать в Label Studio, но потом поняли, что хотим слишком много своего функционала, поэтому сделали свой инструмент, который был бы максимально удобен для разметки классификации товаров на полках магазинов.
Разметку начинали делать в Label Studio, но потом поняли, что хотим слишком много своего функционала, поэтому сделали свой инструмент, который был бы максимально удобен для разметки классификации товаров на полках магазинов.
О том, как делать не слишком много и не слишком мало разметки, будет также отдельная статья. Поэтому здесь сосредоточимся на результате разметки: с каждой камеры один кадр за несколько дней (в среднем) будет размечен, то есть для каждого кропа будет присвоен правильный product_id.
В разметке бывают ошибки, это нормально. Но мы на определённом этапе поняли, что для некоторых категорий товаров ошибки разметки — это чуть ли не самая большая проблема, потому что в остальном пайплайн работал для этих товаров хорошо.
Пробовали разные способы очистки ошибок разметки: автоматический (например, поиск выбросов в каждом классе с помощью Cleanlab, кластеризацию эмбеддингов и тому подобное) и ручной (сужение списка классов до самых «подозрительных», визуализация их в FiftyOne, ручное удаление и переразметка). Но из-за того, что многие классы похожи друг на друга, автоматическая очистка работала довольно нестабильно, и соблюсти баланс между высоким precision и нормальным recall никак не удавалось. В итоге, к сожалению для нас, ручная очистка оказалась наиболее эффективна…
В разметке бывают ошибки, это нормально. Но мы на определённом этапе поняли, что для некоторых категорий товаров ошибки разметки — это чуть ли не самая большая проблема, потому что в остальном пайплайн работал для этих товаров хорошо.
Пробовали разные способы очистки ошибок разметки: автоматический (например, поиск выбросов в каждом классе с помощью Cleanlab, кластеризацию эмбеддингов и тому подобное) и ручной (сужение списка классов до самых «подозрительных», визуализация их в FiftyOne, ручное удаление и переразметка). Но из-за того, что многие классы похожи друг на друга, автоматическая очистка работала довольно нестабильно, и соблюсти баланс между высоким precision и нормальным recall никак не удавалось. В итоге, к сожалению для нас, ручная очистка оказалась наиболее эффективна…
Решение v0: embedder + search space
Classification vs Metric Learning
Начинаем думать о том, как решать задачу классификации товаров в нашем контексте.
Дано:
Необходимо научиться классифицировать кропы товаров.
Самый очевидный подход - решать эту задачу как классификацию, то есть, имея каталог в 20к продуктов обучить модель, которая бы выдавала нам распределение вероятностей по этому каталогу.
Решается легко, но есть большая проблема: ассортимент постоянно меняется, и появляются новые продукты, о которых наш обученный классификатор ничего не знает. Поэтому для них он предсказывает один из старых классов.
Решение - перейти от парадигмы классификации к парадигме metric learning. Это когда мы вместо того, чтобы обучать модель предсказывать распределение вероятностей, мы обучаем модель (эмбеддер), которая для каждого входного изображения будет выдавать нам некое представление (эмбеддинг).
Далее мы его будем сравнивать с существующими эмбеддингами размеченных кропов (множество существующих эмбеддингов разметок - это search space) и таким образом выбирать правильный класс.
Если появляется новый продукт, размечается несколько его экземпляров и они попадают в search space, то, при условии что наш эмбеддер обучен хорошо, он выдаст эмбеддинг, близкий к этим кропам из search space, и мы в итоге правильно предскажем класс.
Дано:
- фотографии с камер,
- кропы по детекциям от YOLO,
- разметки раз в несколько дней.
Необходимо научиться классифицировать кропы товаров.
Самый очевидный подход - решать эту задачу как классификацию, то есть, имея каталог в 20к продуктов обучить модель, которая бы выдавала нам распределение вероятностей по этому каталогу.
Решается легко, но есть большая проблема: ассортимент постоянно меняется, и появляются новые продукты, о которых наш обученный классификатор ничего не знает. Поэтому для них он предсказывает один из старых классов.
Решение - перейти от парадигмы классификации к парадигме metric learning. Это когда мы вместо того, чтобы обучать модель предсказывать распределение вероятностей, мы обучаем модель (эмбеддер), которая для каждого входного изображения будет выдавать нам некое представление (эмбеддинг).
Далее мы его будем сравнивать с существующими эмбеддингами размеченных кропов (множество существующих эмбеддингов разметок - это search space) и таким образом выбирать правильный класс.
Если появляется новый продукт, размечается несколько его экземпляров и они попадают в search space, то, при условии что наш эмбеддер обучен хорошо, он выдаст эмбеддинг, близкий к этим кропам из search space, и мы в итоге правильно предскажем класс.
Для того, чтобы пайплайн заработал в такой парадигме, нам нужны 2 вещи: эмбеддер и search space.
Эмбеддер & ArcFace
Мы довольно много экспериментировали с разными небольшими моделями (ConvNext, ViT, Swin и др.), но по балансу скорости в ограниченных ресурсах и качества мы выбрали ViT-Base-32.
Но как обучать модель, которая будет давать хорошие эмбеддинги? Хорошая новость в том, что эмбеддер можно обучать как классификатор, потому что задача классификации с правильно устроенной функцией потерь естественным образом учит модель формировать компактные и хорошо разделённые эмбеддинги для каждого класса.
Но как обучать модель, которая будет давать хорошие эмбеддинги? Хорошая новость в том, что эмбеддер можно обучать как классификатор, потому что задача классификации с правильно устроенной функцией потерь естественным образом учит модель формировать компактные и хорошо разделённые эмбеддинги для каждого класса. В ArcFace используется additive angular margin loss - модифицированная версия softmax, которая работает не с логитами, а с углами между нормированными эмбеддингами и весами классов. ArcFace «толкает» эмбеддинги одного класса ближе к своему центру на гиперсфере и одновременно увеличивает угловой зазор между классами, обеспечивая более строгую геометрическую структуру в пространстве признаков.
Плюсы такого подхода в том, что эмбеддинги становятся значительно более дискриминативными:
- классы разделены по углам, а не просто по евклидовой дистанции;
- внутри класса вариативность меньше;
- межклассовые расстояния стабильно больше.
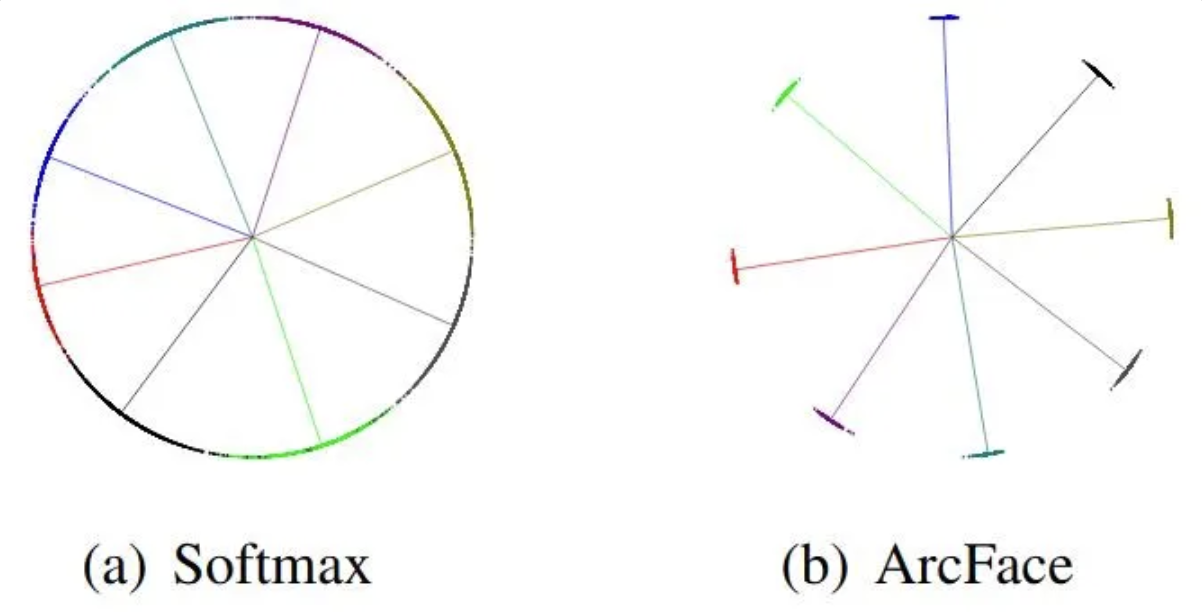
Эмбеддинги, полученные моделью с ArcFace, имеют большие расстояния между классами и небольшие внутри класса, поэтому их легко отделять друг от друга. Source
Немного деталей обучения эмбеддера:
- Размер эмбеддинга 512 - вполне стандартный;
- Batch size - чем больше, тем лучше, поскольку получается в один батч помещать побольше групп товаров. При переходе с RTX3090 на H100 (и увеличение батчсайза в несколько раз) даже качество немного увеличилось;
- Сэмплирование - batch balanced по компании, каждого класса по 4 кропа. У нас было 2 вендора, поэтому в одном батче были только кропы из одной компании, и на инференсе мы фильтровали поиск также по компании. В планах еще сделать сэмплирование по категориям, чтобы в одном батче была в основном одна категория (отличать колу от печенья нет смысла, а вот одно печенье от другого - есть смысл);
- Претрейн - экспериментально выяснили, что лучше сначала обучать претрейн на датасете rp2k, а потом уже файнтюнить на нашем датасете.
Search space
Search space должен выполнять в основном одну функцию: для заданного эмбеддинга максимально быстро искать ближайшие к нему эмбеддинги (точным поиском KNN или приблизительным ANN). Есть разные реализации подобного векторного хранилища, среди них Faiss, Milvus, Qdrant, даже в Redis есть векторная база данных. Мы остановились на Qdrant, так как его относительно легко настраивать и масштабировать, и в целом он представлял весь нужный нам функционал.
Начинаем потихоньку выстраивать пайплайн. Берем все размеченные кропы, прогоняем их через эмбеддер, получаем эмбеддинги, кладем в Qdrant. Он позволяет нам хранить вместе с векторами еще полезную нагрузку или payload (например, product_id, bbox_id и любую другую мету), а также быстро фильтровать по этим данным с помощью индексирования.
Но как быстро искать ближайшие векторы? Если у нас в search space 2 миллиона векторов, просто считать cosine similarity (косинусное сходство) между целевым эмбеддингом и всеми эмбеддингами будет очень долго. Во-первых, можно сильно сузить область поиска с помощью фильтрации по payload (например, только по товарам из текущего магазина или текущей категории). Во-вторых, можно использовать приблизительный поиск, он же approximate nearest neighbors или ANN. Его можно делать несколькими способами, но в Qdrant используется Hierarchical Navigable Small World (HNSW).
Но как быстро искать ближайшие векторы? Если у нас в search space 2 миллиона векторов, просто считать cosine similarity (косинусное сходство) между целевым эмбеддингом и всеми эмбеддингами будет очень долго. Во-первых, можно сильно сузить область поиска с помощью фильтрации по payload (например, только по товарам из текущего магазина или текущей категории). Во-вторых, можно использовать приблизительный поиск, он же approximate nearest neighbors или ANN. Его можно делать несколькими способами, но в Qdrant используется Hierarchical Navigable Small World (HNSW).
Если вкратце, то HNSW - это структура для быстрого поиска ближайших соседей, построенная как многоуровневый граф, где верхние уровни дают грубую навигацию, а нижние - точный локальный поиск. Поиск происходит сверху вниз: сначала Qdrant находит приближенную область, где находится ближайший вектор, а затем уточняет результат на нижнем уровне. Это позволяет очень быстро найти наиболее подходящие вектора без перебора всей базы.
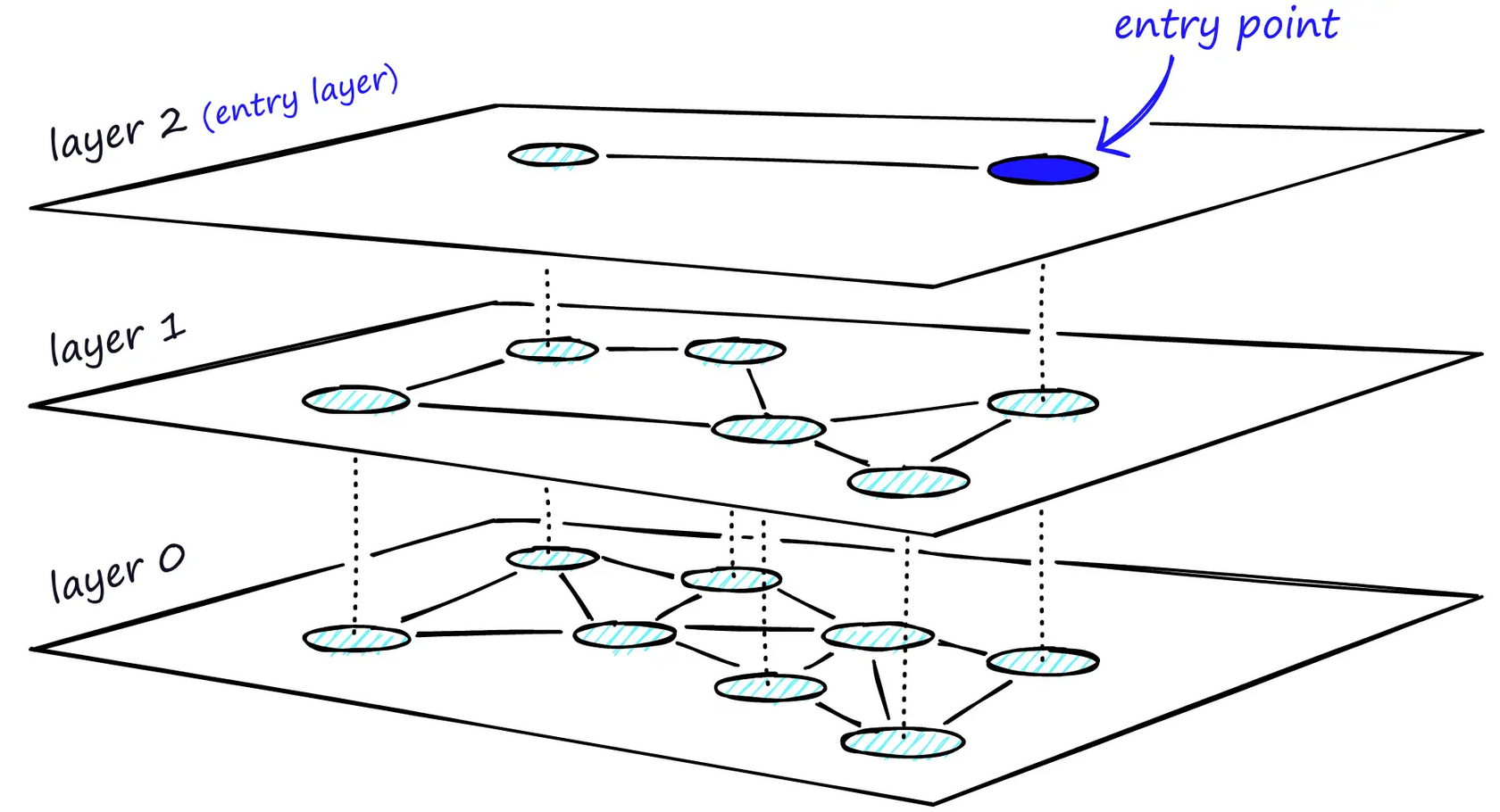
Многоуровневый граф в HNSW. Source (отличная статья, советую!)
Пайплайн v0: голый эмбеддер
Пайплайн получается довольно простой: для каждого кропа с каждой камеры мы считаем эмбеддинг. Если этот кроп размечается, то мы кладем его вместе с эмбеддингом и payload в Qdrant; если нет - идем в search space и ищем для него ближайший вектор, достаем product_id из payload и получаем предсказание для этого кропа. Такой пайплайн дал нам примерно 85% accuracy по всем кропам, то есть явно есть куда расти.
Как считается метрика? В продакшн-пайплайне у нас нет классического тестового датасета с «чистыми» ground truth разметками: ассортимент постоянно меняется, товары появляются и исчезают, а разметка обновляется инкрементально.
Поэтому основная E2E-метрика, которую мы можем считать автоматически, - это доля предсказаний, которые разметчик не изменил. Разметчик получает предразметку в виде top-1 предсказания текущего пайплайна. Если он подтверждает его, мы считаем такое предсказание корректным. Таким образом, метрика показывает, насколько часто система сразу даёт разметчику приемлемый результат, без необходимости ручной коррекции.
Эта метрика хорошо отражает реальную полезность системы в продакшне (экономию времени разметчиков и стабильность пайплайна). Однако у неё есть известное ограничение: в спорных случаях разметчики склонны подтверждать предсказание пайплайна, даже если они не полностью уверены в его корректности. Поэтому метрика имеет bias в сторону текущего решения и не является «чистой» accuracy в классическом ML-смысле. Тем не менее, при сравнении разных версий пайплайна в одинаковых условиях она хорошо коррелирует с реальным улучшением качества.
Примеры
Посмотрим на интересные кейсы ближайших кропов из search space, их cosine similarity и product_id:

Майонез лежит, а не стоит, поэтому ищется с трудом

2 часто путающихся товара - сок с апельсином и грейпфрутом

Квест: нужно отличить банку 160г от банки 190г.

Кроп затемнен, поэтому в топ-5 у нас появляется аж 5 разных продуктов.
Решение v1: v0 + realgram
Проблемы подхода v0
Проблем довольно много. Как хорошо ни обучай эмбеддер, он все равно будет путать похожие товары друг с другом (например, вода 0.5л и вода 1л; приправа для курицы и для картошки; апельсины и мандарины). Иногда дело в качестве снимков с камер и в освещении, иногда эти товары буквально никак не отличить друг от друга даже человеческим взглядом (если упаковка/бутылка повернуты спиной). Но факт в том, что чисто визуальных признаков для определения правильного класса явно недостаточно.
Дополняем визуальный контекст пространственным
Каждый кроп у нас существует не в вакууме - он живет на полке, на которой периодически (в среднем раз в несколько дней) делается разметка. Поэтому у нас есть довольно сильный сигнал “что было размечено на этой полке за последнее время?”, который мы пока что никак не используем.
Так что идея простая: передать этот сигнал в наш пайплайн, потому что он явно должен нам помогать. Сделать это чуть сложнее, чем кажется, поскольку нам нужно не просто использовать независимо визуальные фичи (классы/скоры из search space) и пространственные (разметки этой полки), а объединить их, чтобы взять лучшее от обоих способов.
В идеале мы хотим получить алгоритм, который будет обладать такими свойствами:
Так что идея простая: передать этот сигнал в наш пайплайн, потому что он явно должен нам помогать. Сделать это чуть сложнее, чем кажется, поскольку нам нужно не просто использовать независимо визуальные фичи (классы/скоры из search space) и пространственные (разметки этой полки), а объединить их, чтобы взять лучшее от обоих способов.
В идеале мы хотим получить алгоритм, который будет обладать такими свойствами:
- Учитывать в первую очередь классы и скоры из search space.
- Учитывать последние разметки этой полки с учетом таких параметров:
b. Насколько разметка устарела по времени. Разметка двухдневной давности должна иметь больший вес, чем разметка двухнедельной давности.
Такой алгоритм был реализован под названием realgram (примерно как planogram - это то, что по плану должно находиться на полке, а realgram - это то, что реально там находится).
Пайплайн v1: к эмбеддеру добавляем realgram
Пайплайн v0 остается пока без изменений: для кропа считаем эмбеддинг, идем в Qdrant и достаем оттуда ближайшие кропы и их payload. Дальше:
- Для текущей полки собираем объединенный список товаров из разметок за последние 30 дней следующим образом: если в первой разметке были товары 1, 2, 2, 3, а во второй разметке товары 2, 2, 3, 4, то в объединенном списке будут товары 1, 2, 2, 3, 4, то есть среди соседних разметок для каждого уникального товара берем максимальное количество вхождений. Если на этой полке вообще не было разметок, то realgram вырождается и остается чистый пайплайн v0.
- Для каждого товара из списка считаем коэффициент устаревания (гиперпараметр - насколько быстро устаревают разметки) и коэффициент пересечения по координатам с текущим кропом (еще один гиперпараметр - насколько сильно учитывать пересечения).
- Для каждого товара из списка получаем итоговый коэффициент, учитывая коэффициенты устаревания и пересечения, а затем для каждого уникального товара из списка (так как там могут быть повторы) считаем максимальный итоговый коэффициент.
- К исходным скорам (scores) товаров из Qdrant добавляем итоговый коэффициент, умноженный на коэффициент realgram (гиперпараметр - насколько мы верим разметкам).
- Получаем финальные скоры, которые включают в себя скоры из Qdrant и скоры realgram, и по топ-1 определяем предсказание.
Звучит так, будто много коэффициентов (на самом деле их еще больше), и это действительно не идеально, поскольку приходится подбирать их “на глаз” или с помощью Optuna. Но оно того стоит, потому что итоговая метрика с помощью такого алгоритма с подобранными гиперпараметрами выросла с 85% до 92%!
Визуализировать realgram сложно, но попытка это сделать выглядит вот так:
Визуализировать realgram сложно, но попытка это сделать выглядит вот так:
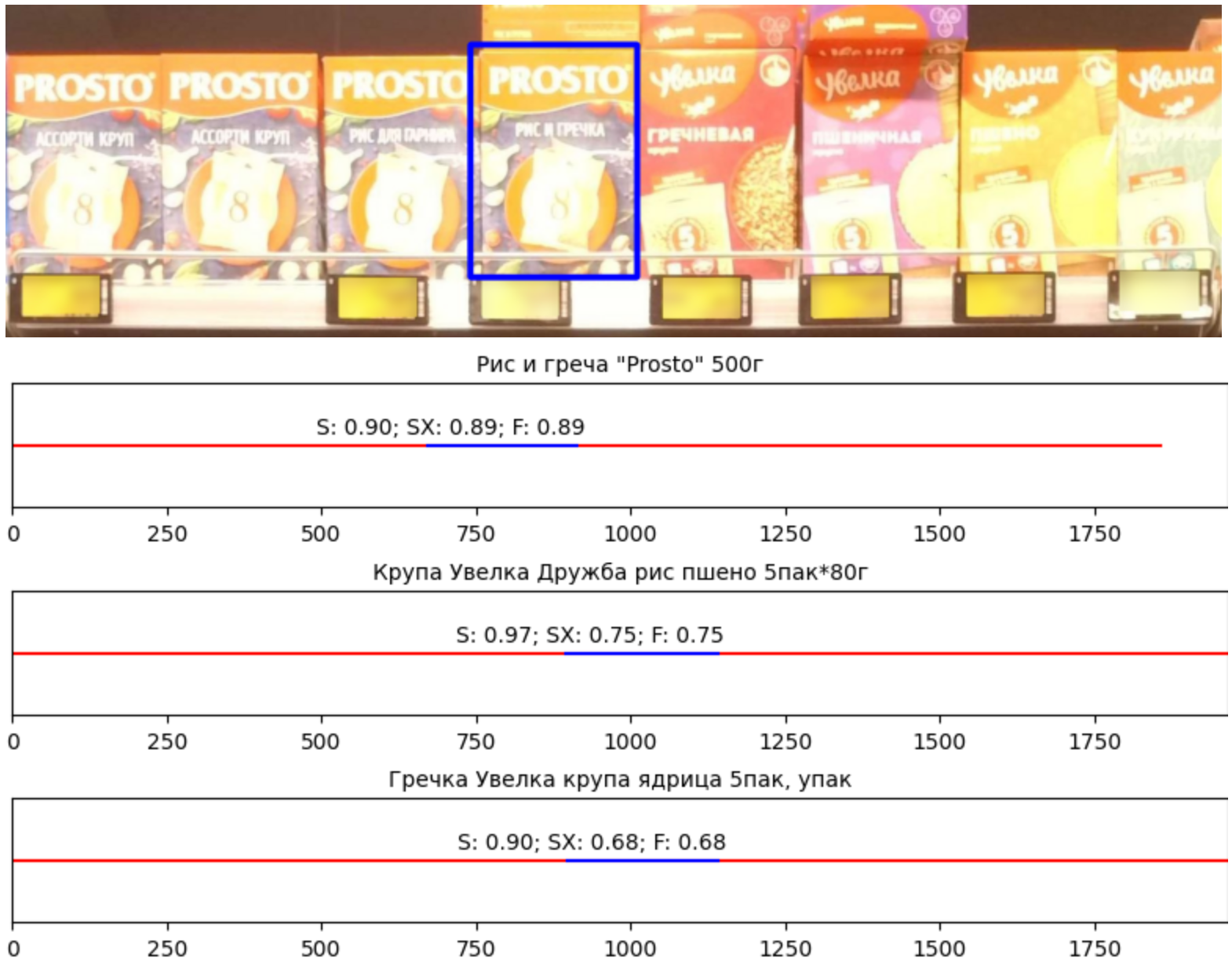
Realgram скоры для выделенного кропа: “Рис и греча” больше всего подходят по координатам и по свежести, а “Дружба” и “Гречка ядрица” тоже подходят по свежести, но по пересечению меньше меньше (S - коэффициент устаревания, SX - коэффициент устаревания вместе с пересечением)
Примеры
Посмотрим на некоторые примеры, в которых эмбеддер предсказывает неправильно, а realgram исправляет предсказание в правильную сторону:

Разница в cosine similarity минимальная, так как отличается только текст на фото, но realgram подсказывает по местоположению

Тут отличие в объеме, эмбеддер такого не видит, но realgram подсказывает

Опять же очень похожие значение cosine similarity, но видимо в более свежих разметках был правильный товар (или по координатам он был ближе)

Тут вообще нельзя однозначно сказать, что за товар, но наверняка этикетки и местоположение отличается (разметчику здесь виднее)
Результаты
Мы получили довольно неплохой baseline, пройдя путь от простого эмбеддера и search space с метрикой 85% до контекстного алгоритма realgram с метрикой 92%.
Но проблемы все еще остаются:
Но проблемы все еще остаются:
- Качество все еще далеко от идеала - на сложных кропах с плохим освещением или частично скрытым товаром система по-прежнему предсказывает почти случайно, учитывая только контекст разметок на полке.
- Большое количество “миганий”, когда на соседних фото с одной камеры в каком-то месте товар не изменился, но при этом предсказание для него меняется из-за волатильности топа search space.
- Много гиперпараметров - в realgram есть с десяток параметров, которые нужно подбирать вручную или с помощью Optuna, но хотелось бы иметь более универсальный алгоритм, который подбирал эти гиперпараметры сам.
- Много подобных кейсов: топ-1 из search space неправильный, но с высоким скором (выше realgram правильного товара), при этом правильные классы находятся в топе 2–10. Если бы мы учитывали не только топ-1, но и общую картину, то могли бы это исправить.
В следующих двух статьях расскажем вам про то, как мы улучшали этот пайплайн с помощью трекинга и классификатора второго уровня.
Благодарим за подготовку материала наших инженеров компьютерного зрения: Александра Коротаевского и Артема Сметанина.

