


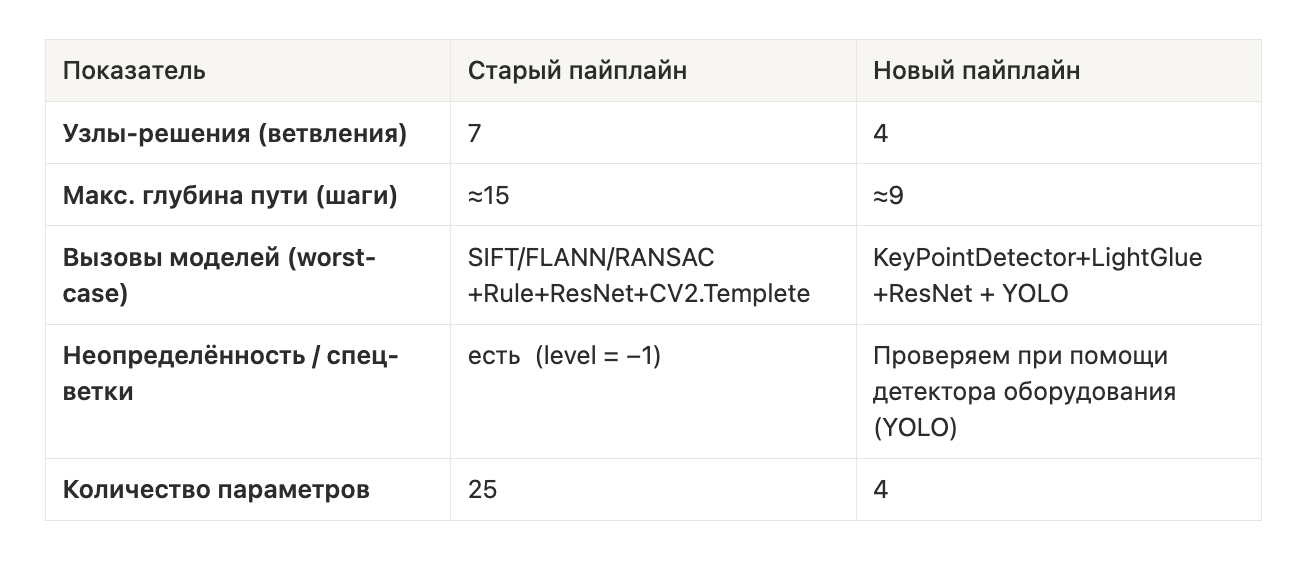
Попытка «отдать всё нейросети»: ResNet по дельта-изображениям
Следующий шаг – попытаться заменить часть эвристик на нейросетевой классификатор.
Идея: взять пару кадров (image1, image2), вычислить разностное изображение (например, delta = image2 - image1 по пикселям) и обучить CNN-классификатор, который по этому дельта-кадру предсказывает класс сдвига: without, normal или high.
Идея: взять пару кадров (image1, image2), вычислить разностное изображение (например, delta = image2 - image1 по пикселям) и обучить CNN-классификатор, который по этому дельта-кадру предсказывает класс сдвига: without, normal или high.
Датасет и аугментации. Для обучения такого классификатора мы сформировали выборку из реальных и синтетических данных. Во-первых, выгрузили все пары, которые текущий детектор однозначно относил к классу without (и убедились в их корректности) – это базовый набор отсутствия сдвига. Во-вторых, сгенерировали дополнительный набор пар с помощью аугментаций: к одному кадру из пары применяли случайные смещения и повороты (в ~80% изображений) для имитации сдвигов. Генерировались два типа искусственных сдвигов: normal-сдвиги (небольшие, ± несколько пикселей, лёгкие повороты) и high-сдвиги (более крупные смещения и углы, имитирующие сильный уход камеры).
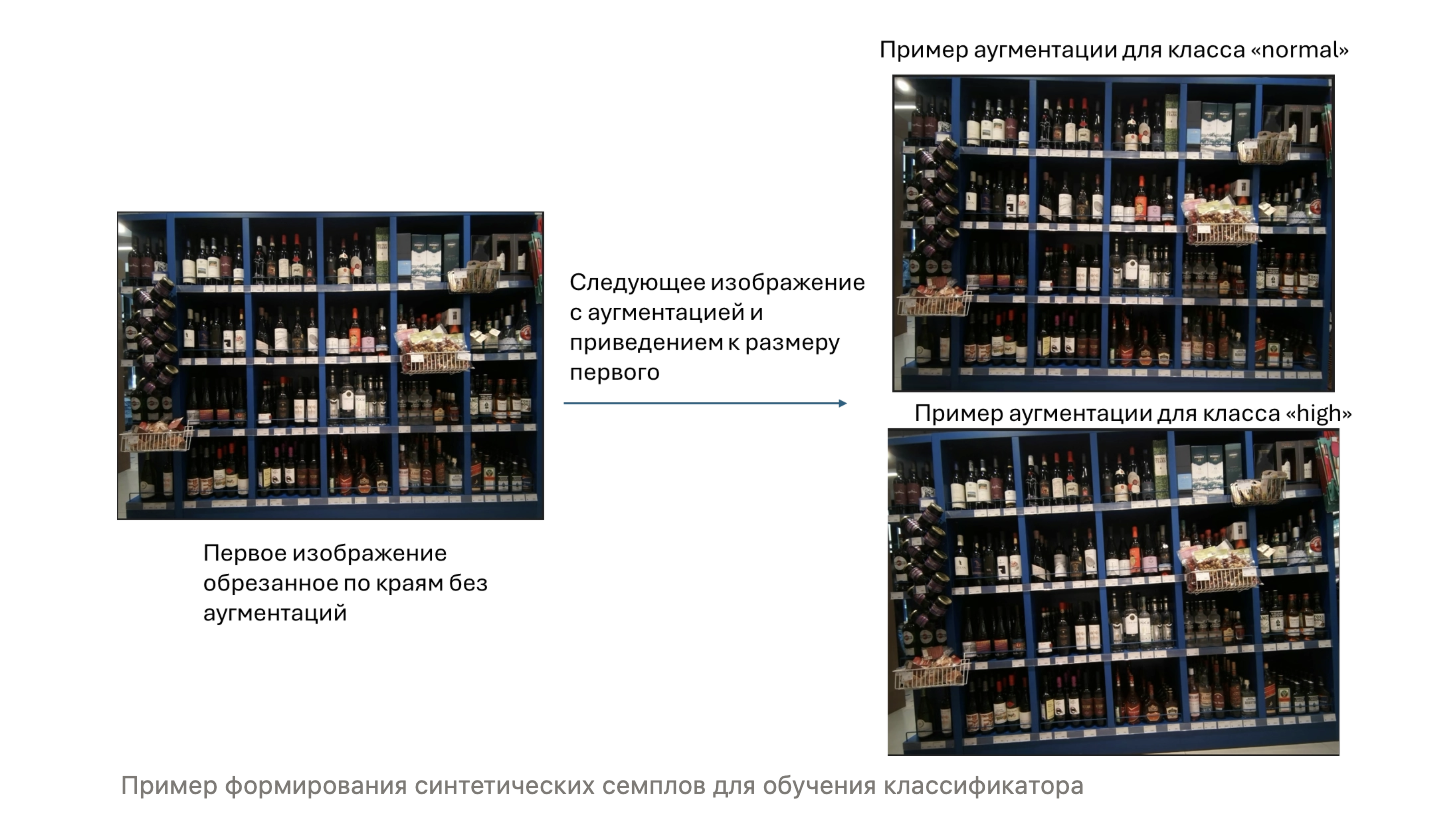
Модель. В качестве классификатора сдвигов использовалась архитектура ResNet34. На вход модель получала дельта-изображение (разницу двух кадров), на выходе – один из трёх классов: without, normal или high. Обучение проводилось по стандартной схеме (кросс-энтропия, Adam). Метрики на валидации показывали высокую точность: например, precision/recall для классов были около 0.90–0.94 для without/normal/high. На продакшн-кейсах классификатор тоже демонстрировал понимание разницы между сменой ассортимента и геометрическим сдвигом. Ниже приведены примеры его предсказаний на валидационных данных и синтетике:
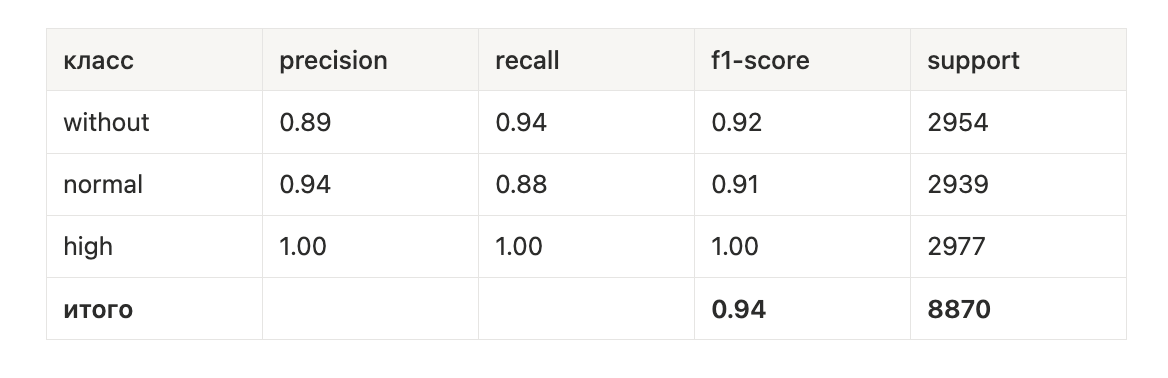
Класс high распознается почти идеально, без ложных срабатываний и пропусков на этой выборке. Для классов without и normal метрики немного ниже, но тоже достаточно высокие и при этом сбалансированные по precision и recall. В сумме это дает общую точность около 94 процентов на валидации.
Далее показаны примеры предсказаний ResNet модели на валидационных продакшн кейсах. Примеры изображений и предсказаний.
Далее показаны примеры предсказаний ResNet модели на валидационных продакшн кейсах. Примеры изображений и предсказаний.





Важно отметить, что получилось успешно определять смену продуктов и отделять ее от реальных сдвигов.

Мы использовали классификатор только для тех случаев, которые попадали под правила и из-за этого уходили в модерацию. Модель помогала уточнить ситуацию и отделить действительно проблемные пары от условно нормальных. Распределение SIFT само по себе не давало нам точного направления сдвига, которого достаточно для автоматического сдвига viewport, поэтому поверх него мы добавили дополнительный этап с cv.TemplateMatching.
TemplateMatching применялся к уже отобранным парам. Мы задавали пороги совпадения, пытались аккуратно совместить фрагменты изображения и по результату оценивали сдвиг. Если удавалось получить устойчивое совпадение и вычислить вектор сдвига, мы применяли этот метод как альтернативу стандартному автофиксу вьюпортов. В остальных случаях пара по прежнему уходила на ручную проверку.
Что получилось
По offline-метрикам и локальным экспериментам было видно, что:
- ResNet прилично различает without / normal / high на синтетике;
- класс high детектируется довольно уверенно;
- по сравнению с чистым SIFT + пороги уменьшается количество задач модерации.
Например, по одному из экспериментов:
- без классификатора: 241 задач (high + unknown);
- с классификатором (without + пороги): 156 задач (–35%);
- классификатор + autofix: 86 задач (–45% от исходного числа).
Но на прод-распределении стало очевидно, что у подхода есть ограничения:
- при сложных ракурсах (перспектива, наклоны) геометрия дельты становится нелинейной, и ResNet тоже ошибается.
- Модель может путать normal и high сдвиги, могут создаваться лишнее тикеты=
В итоге мы оставили ResNet как дополнительный сигнал, но не стали строить всю логику вокруг него. Геометрический пайплайн и правила по распределениям SIFT по прежнему играли ключевую роль, а классификатор лишь помогал уточнять сложные кейсы на выходе из правил.
При этом у всего пайплайна оставались заметные минусы. Он по прежнему плохо работал на сложных сдвигах, например при диагональных и перспективных смещениях камеры. Автофикс вьюпортов часто получался неточным, особенно когда сдвиг не укладывался в простую модель по осям X и Y. Чувствительность к мелким сдвигам была слабой, часть небольших но важных смещений просто не детектировалась. Плюс сохранялись ложные срабатывания, когда система видела сдвиг там, где по сути менялись только товары или освещение.
Новый пайплайн: SuperPoint + LightGlue + детектор оборудования
Следующий крупный шаг мы сделали уже спустя три месяца, когда решили пересобрать пайплайн с нуля, чтобы устранить оставшееся проблемы.
Зачем было что-то менять, если всё уже работает?
После всех итераций с SIFT, правилами и ResNet стало понятно, что сам фундамент пайплайна уже ограничивает нас. Мы по-прежнему упирались в сложные сдвиги с перспективой, неточный автофикс и слабую чувствительность к мелким смещениям. Плюс в коде было много ручных порогов и разветвлений, которые сложно сопровождать и переносить на новые магазины и камеры.
Следующий шаг был логичным: не пытаться бесконечно чинить старый пайплайн, а заменить базовый способ поиска соответствий между кадрами на более современный. Для этого мы собрали новый детектор сдвигов на связке SuperPoint + LightGlue и интегрировали в него детектор оборудования.
Вместо SIFT: SuperPoint + LightGlue
В старом пайплайне всю геометрию нам давали SIFT-кейпоинты и KNN-матчер.
В новом пайплайне тот же шаг реализован через отдельный класс LightGlueMatcher подробнее по ссылке:
- Для обоих изображений считаются фичи SuperPoint. Внутри это примерно так:
- картинка приводится к RGB,
- конвертируется в градации серого,
- нормируется и подаётся в SuperPoint, который возвращает координаты ключевых точек и дескрипторы.

2._LightGlue получает на вход два набора фичей и считает матчи.
В отличие от классического KNN, он умеет учитывать контекст и структуру сцены, а не только локальное сходство дескрипторов.
В отличие от классического KNN, он умеет учитывать контекст и структуру сцены, а не только локальное сходство дескрипторов.

3._Матчи фильтруются по качеству.
При сопоставлении точек отбрасываются точки с низкой уверенностью, остаются только «валидные» соответствия, по которым можно оценивать сдвиг.
4._По валидным матчам считается вектор сдвига.
Берутся координаты сопоставленных точек на первом и втором изображении, считается разность этих точек, потом берется медианный сдвиг. Этот сдвиг сначала считается в координатах ресайзнутой картинки, потом пересчитывается обратно в пиксели оригинального разрешения. На выходе у нас три вещи:
То есть там, где раньше работал SIFT + RANSAC, теперь работает SuperPoint + LightGlue. Логика та же, но качество матчей и устойчивость к перспективе и изменениям контента намного выше.
При сопоставлении точек отбрасываются точки с низкой уверенностью, остаются только «валидные» соответствия, по которым можно оценивать сдвиг.
4._По валидным матчам считается вектор сдвига.
Берутся координаты сопоставленных точек на первом и втором изображении, считается разность этих точек, потом берется медианный сдвиг. Этот сдвиг сначала считается в координатах ресайзнутой картинки, потом пересчитывается обратно в пиксели оригинального разрешения. На выходе у нас три вещи:
- модуль сдвига,
- сам вектор [dx, dy],
- количество валидных матчей.
То есть там, где раньше работал SIFT + RANSAC, теперь работает SuperPoint + LightGlue. Логика та же, но качество матчей и устойчивость к перспективе и изменениям контента намного выше.
2._Первичная оценка уровня сдвига по модулю
Следующий шаг в пайплайне остался концептуально тем же, что и раньше.
По модулю вектора сдвига мы сначала грубо решаем, в каком диапазоне мы находимся.
Это делает отдельная функция:
- если модуль меньше порога without (например, 1 пиксель), кадр считается без сдвига, код уровня 1 (WITHOUT) могут быть маленькие колебания из-за дрифта фокуса;
- если модуль меньше либо равен порогу normal (например, 10 пикселей), это нормальный сдвиг, код уровня 0.5;
- если модуль больше, это кандидат в сильный сдвиг, код уровня -1 (HIGH).
На этом этапе мы ещё ничего не знаем про смену продуктов, препятствия и прочее, это просто «первый взгляд» на число пикселей. Дополнительно учитывается количество матчей. Если валидных матчей мало (в коде порог 100), то мы не доверяем оценке сдвига и сразу отправляем пару в категорию EXTRA, без дальнейшей проверки. Это позволяет не тратить ресурсы на тяжёлые шаги, если само вычисление сдвига получилось ненадёжным.
3._ResNet как фильтр для сложных HIGH-кейсов
Старый ResNet-классификатор мы не выбросили, а встроили внутрь нового пайплайна, но на другом месте.
Теперь он не пытается сам делать всю работу, а используется точечно:
- Если по модулю сдвига уровень получился HIGH, мы подаём пару кадров в ResNet.
- without,
- normal,
- high,
- perspective (отдельный класс для перспективных и диагональных сдвигов).
По сути мы разделили старый класс high на два подкласса:
- high это в основном линейные сдвиги, которые хорошо описываются простым вектором смещения;
- perspective нелинейные, более сложные сдвиги с поворотами и перспективой. Раньше все такие случаи жили в одном классе high, сейчас мы различаем их явно.

2._В зависимости от предсказания мы ветвимся:
Таким образом, ResNet стал фильтром внутри ветки high, а не отдельным параллельным классификатором. Он помогает отсеять случаи, когда по модулю сдвиг выглядит большим, но по факту это шум, смена контента или неаккуратная оценка.
- если ResNet говорит normal, мы понижаем уровень до NORMAL, считаем что сильного сдвига нет, и не запускаем ничего тяжелее;
- если ResNet говорит without, мы помечаем кейс как EXTRA, то есть по сути тут есть конфликт между ResNet и первым этапом и тут может быть закопан сложный сдвиг;
- если ResNet говорит perspective, мы явно помечаем категорию как перспективный сдвиг и сразу отправляем его в категорию EXTRA чтобы отправить его на модерацию
- если ResNet подтверждает high, значит это действительно сильный сдвиг, и дальше мы включаем ещё одну проверку через детектор оборудования чтобы проверить автофикс.
Таким образом, ResNet стал фильтром внутри ветки high, а не отдельным параллельным классификатором. Он помогает отсеять случаи, когда по модулю сдвиг выглядит большим, но по факту это шум, смена контента или неаккуратная оценка.
4._Детектор оборудования для проверки корректности сдвига
В новом пайплайне мы дополнительно используем детектор торгового оборудования как источник устойчивой структурной информации о сцене.
Этот детектор отдельная модель объектной детекции, которая на каждом кадре предсказывает набор прямоугольников с классами и confidence-оценками. Среди классов полки, холодильники, ценовые ленты, ценники, дополнительные объекты на полках.

В отличие от товаров, такие объекты являются конструктивными элементами сцены: при неподвижной камере они либо остаются на месте, либо исчезают только из-за перекрытий, но не «переезжают» сами по себе. Именно это свойство мы используем дальше как геометрическую проверку корректности найденного сдвига камеры.
Из всего набора нас интересуют прежде всего стабильные, конструктивные объекты сцены
- полки и другое торговое оборудование
- ценовые ленты, ценники
то есть то, что не должно исчезать или резко переезжать без реального сдвига камеры.
Дальше мы делаем несколько шагов.
- Сначала отбрасываем детекции, которые находятся вне вьюпортов. Мы берём все боксы оборудования и для каждого считаем пересечение с прямоугольниками вьюпортов по метрике IoU. Если пересечение с каким то вьюпортом больше небольшого порога, считаем, что этот объект «живёт» внутри полезной области, и сохраняем его. Так получаем подмножество боксов внутри вьюпортов на первом и втором кадре.
- Затем применяем рассчитанный вектор сдвига камеры. Все боксы из первого кадра, которые попали во вьюпорты, сдвигаются на этот вектор по координатам. После этого мы сравниваем их с боксами второго кадра. Для каждого сдвинутого бокса ищем на втором кадре лучший по IoU кандидат и считаем совпадание, если IoU выше заданного порога. Так получается общее количество «совпавших» объектов оборудования. Мы смотрим, насколько сильно отличается число объектов и число совпадений между кадрами, не стало ли резко меньше или больше оборудования внутри вьюпортов, чем было.
- Отдельно проверяем классы, которые считаем особенно важными. В текущей конфигурации это ценовые ленты. Мы выбираем все боксы с классом «ценовая лента» на обоих кадрах, снова ограничиваемся только теми, что попали во вьюпорты, и для каждого вьюпорта считаем совпадения по IoU между первым кадром (с учётом сдвига) и вторым. Для ценовых лент правила максимально строгие: для каждого вьюпорта, где на первом кадре были ценовые ленты, на втором кадре после сдвига должны быть такие же ленты с хорошим пересечением. Мы считаем, сколько лент совпало, сколько «пропало» и сколько «лишних» появилось, и сравниваем это с порогами по доле совпадений и допустимому числу пропусков и лишних объектов.
В результате из этой проверки мы получаем набор флагов, по сути ответы на вопросы
- сохранилось ли примерно то же количество оборудования внутри вьюпортов
- совпали ли по положению полки и ценовые ленты после применения сдвига
- нет ли подозрительных случаев, когда много объектов пропало или появилось «с нуля»
Если по этим критериям всё выглядит согласованно, мы считаем, что детекция оборудования подтверждает оценку сильного сдвига. Если же пересечений по IoU мало, сильно расходится количество объектов или ценовые ленты «не попадают» в сдвинутые вьюпорты, такой сдвиг отправляется в модерацию. Такой подход помогает определить был ли успешный авфтофикс.
Оптимизация детектора сдвигов для работы в пайплайне с ограниченными ресурсами
Новый пайплайн с LightGlue и детектором оборудования оказался заметно «тяжелее» старого. В реальном пайплайне он работает не в вакууме, а вместе с детектором товаров и другими сервисами на одном и том же узле localhub, где у нас обычный CPU без отдельной видеокарты. Поэтому следующая задача после качества была очень приземлённой: сделать так, чтобы детектор сдвигов с YOLO-детектором оборудования укладывался в бюджет по времени и ресурсам.
Бутылочным горлышком здесь оказался именно детектор оборудования. Это YOLO-модель, которая для каждого кадра предсказывает полки, холодильники, ценовые ленты и препятствия. Чтобы ускорить её, мы провели серию экспериментов с конвертацией и оптимизацией через OpenVINO. Сценарий был такой. В качестве базовой точки мы взяли PyTorch-модель в формате FP32 и прогнали её на типовом CPU из прод-окружения и на тестовом серверес процессом Xeon.
Затем последовательно попробовали несколько вариантов экспорта в OpenVINO: FP32, FP16 и INT8, с динамическими и статическими размерами входа, а также с разными вариантами рантайма (через ultralytics и через «чистый» OpenVINO без лишнего питоновского оверхеда)
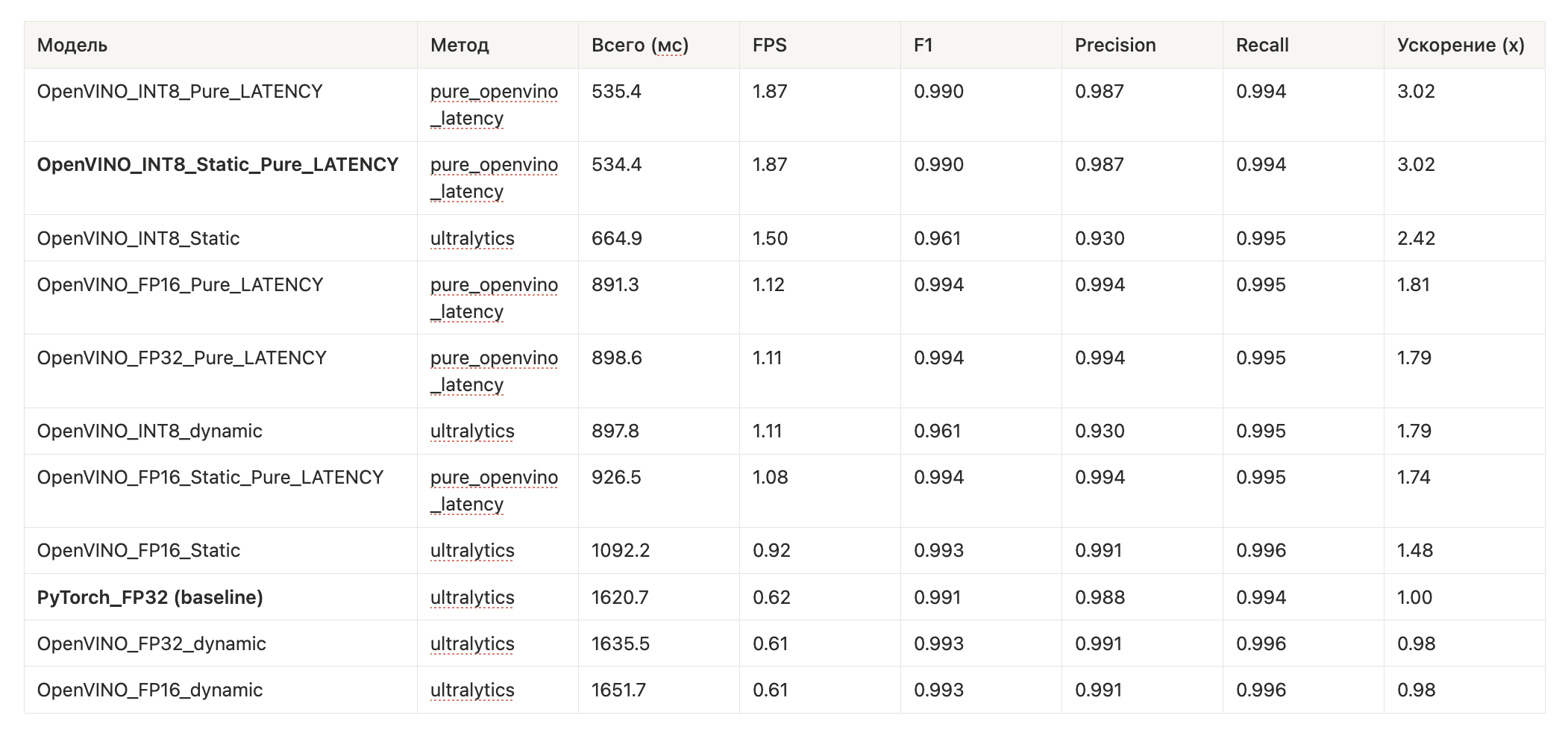
Результаты показали, что уже переход на OpenVINO FP16 даёт заметный выигрыш по скорости без деградации качества: на серверном Xeon и десктопном i7 мы получили прирост FPS примерно на 15–20 процентов, при этом F1-мера детектора оборудования даже слегка выросла относительно исходного PyTorch FP32. Попытка агрессивной INT8-квантизации через стандартный пайплайн дала максимальное ускорение, но цену в виде ощутимого проседания F1. После донастройки и подбора конфигурации мы нашли вариант INT8-модели, который держит F1 около 0.99 и при этом даёт скорость порядка 1.8 кадра в секунду против ~0.6 для исходного PyTorch-детектора. То есть примерно трёхкратное ускорение при практически том же качестве.
При этом для нас было важно проверить не только скорость и качество самого YOLO, но и устойчивость финальных решений пайплайна к его оптимизации.
Мы прогнали оптимизированный детектор оборудования через полный пайплайн SHIFT на большом наборе прод-кейсов и сравнили результаты с базовой PyTorch-версией. При этом логика пайплайна и все пороги оставались неизменными различия могли возникать только из-за численных эффектов оптимизации (квантизация, округления confidence и координат боксов).
На датасете порядка 13 тысяч пар кадров OpenVINO-версия совпадала с базовой PyTorch по типу финального решения (HIGH или EXTRA) примерно в 95% случаев. Оставшиеся 4–5% приходились в основном на пограничные кейсы, где небольшие изменения в детекциях оборудования приводили к более консервативному решению (переходу в EXTRA), а не на пропуски реальных сильных сдвигов.
5. Финальное решение по уровню и категории
Когда у нас есть:
- модуль и вектор сдвига из LightGlue,
- количество матчей,
- решение ResNet (если запускался),
- результат проверки YOLO по оборудованию,
мы принимаем финальное решение.
Логика примерно такая:
- Сначала берём уровень, который дал порог по модулю сдвига.
- Если матчи слабые, понижаем HIGH до NORMAL и помечаем кейс как EXTRA.
- Если ResNet сказал normal или without, пересобираем категорию в их пользу.
- Если ResNet сказал high, но YOLO-проверка показала, что объекты в вьюпортах не ведут себя как при настоящем сильном сдвиге, мы понижаем уровень HIGH до NORMAL через apply_yolo_verification.
- Если и ResNet, и YOLO согласны, что это действительно сильный сдвиг, оставляем HIGH.
На выходе модель отдает:
- финальный level (который дальше используют системы автофикса и модерации),
- модуль и вектор сдвига,
- количество матчей LightGlue,
- результат ResNet,
- результаты детектора оборудования и YOLO-проверки.
Вот подробная схема пайплайна
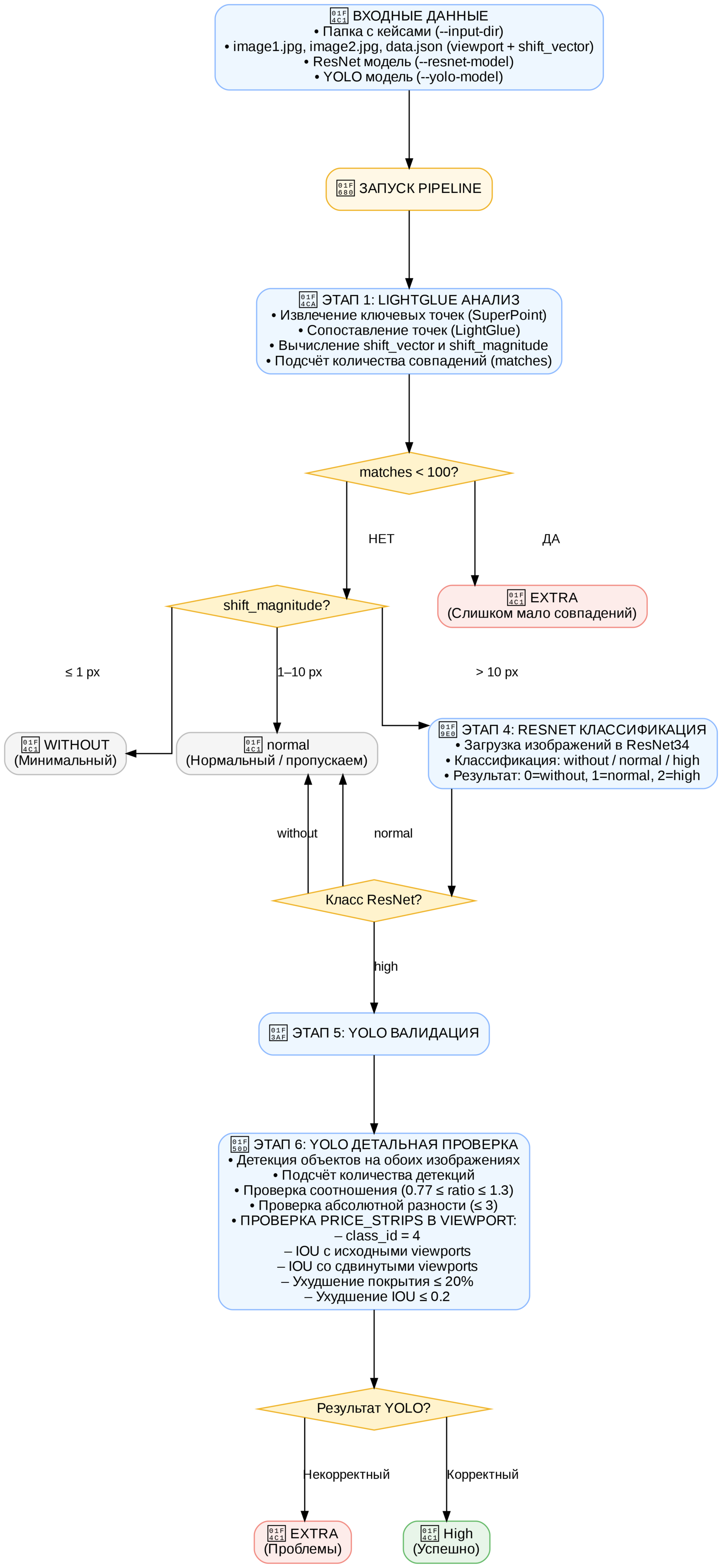
Визуализация работы пайплайна:

При этом мы сознательно упростили количество ручных параметров и ветвлений внутри пайплайна: в сравнении с предыдущей версией число настроек и шагов значительно уменьшилось.
Валидация: LightGlue против старого Shift Detector
Чтобы не спорить на уровне «кажется лучше», мы сравнили новый детектор сдвигов на LightGlue со старым пайплайном на двух наборах пар: компактном и крупном боевом срезе.
Сначала смотрели на компактный набор примерно из пяти тысяч пар. Здесь важнее не абсолютные числа, а то, как распределяются классы. У нового детектора заметная доля пар попадает в класс normal, то есть алгоритм честно фиксирует, что камера немного сдвинулась. При этом основная масса по-прежнему остаётся в without. У старого детектора картина другая: почти всё уходит в without, а normal занимает тонкую полоску в районе нескольких процентов. По сути, старый пайплайн предпочитает считать камеру неподвижной даже там, где есть очевидный нормальный сдвиг.
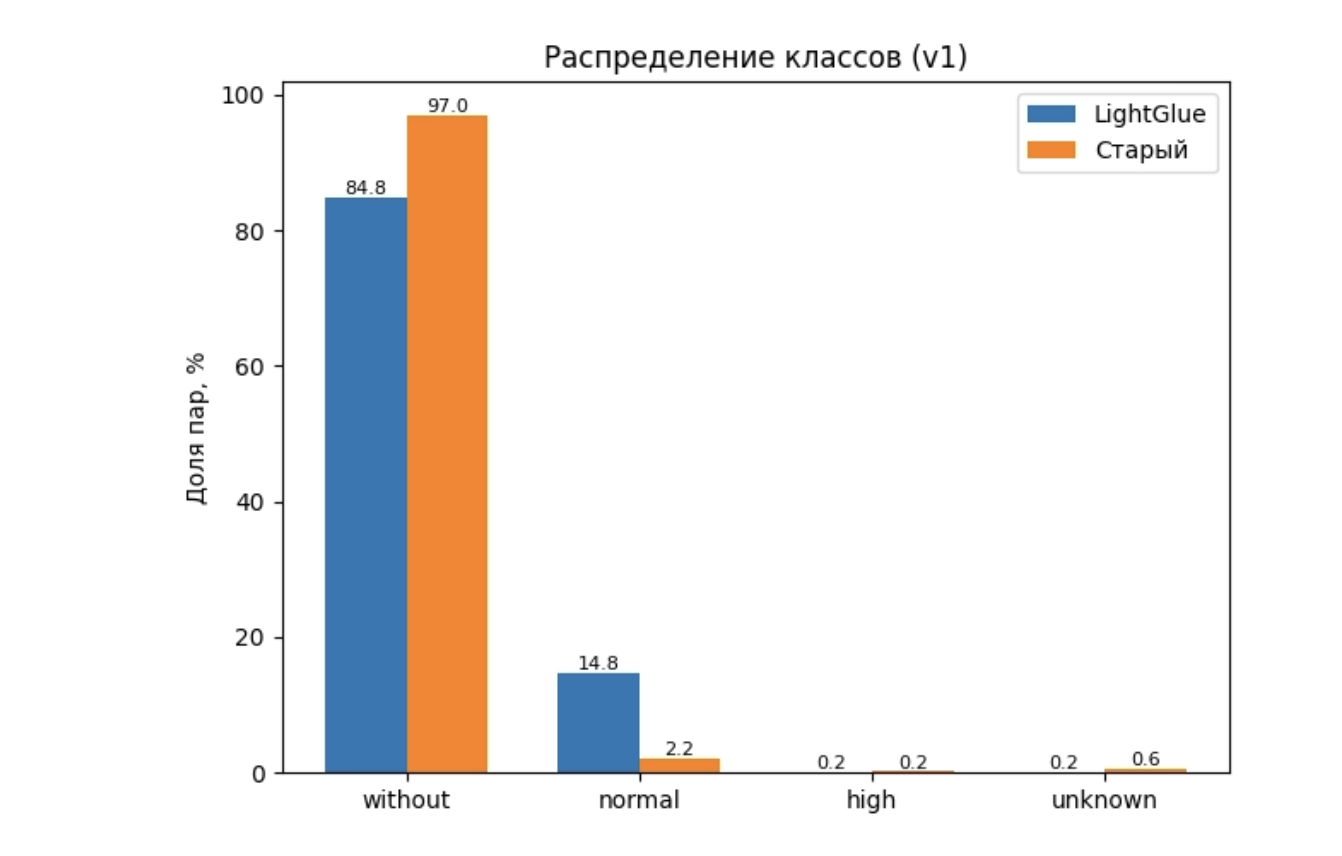
Распределение классов на компактном датасете (LightGlue vs старый детектор)
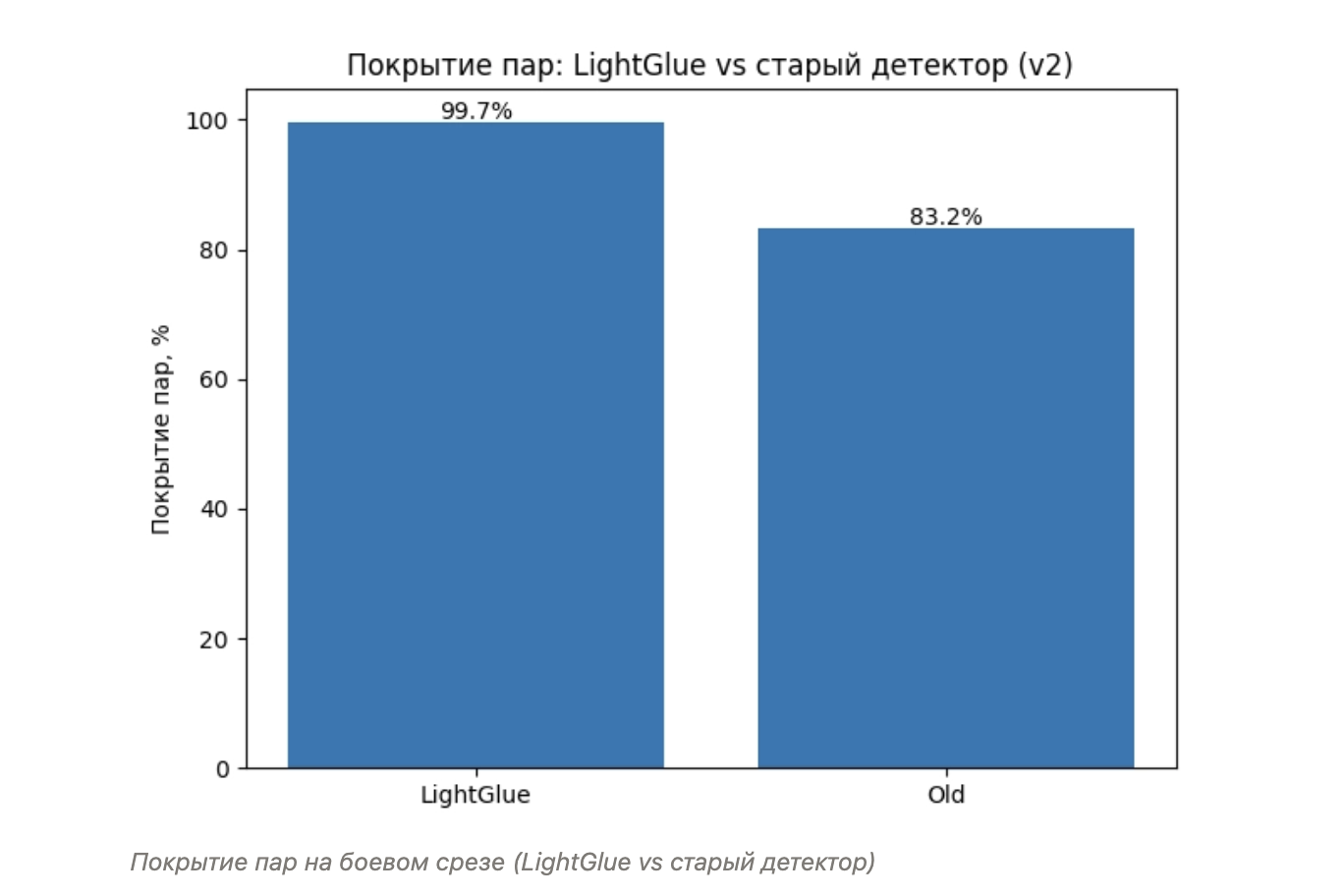
Дальше мы посмотрели на большой боевой срез (порядка 50 тыс. пар). Здесь в первую очередь важна разница по покрытию.
Новый детектор обрабатывает почти все возможные пары кадров, фактически весь поток. Старый пайплайн теряет примерно шестую часть пар в основном в сценах с препятствиями в кадре, когда часть полки закрыта людьми, тележками или коробками.
Причина в том, что старый пайплайн на основе SIFT + RANSAC плохо работает при частичных перекрытиях сцены: количество валидных сопоставлений резко падает, оценка трансформации становится нестабильной, и пара фактически «отбрасывается» как нерешаемая.
Новый пайплайн на SuperPoint + LightGlue устойчив к таким ситуациям. Он способен находить корректные соответствия даже при частичной видимости сцены и продолжать обработку пары, явно классифицируя её как WITHOUT, NORMAL или EXTRA, а не теряя её полностью. Для прод-окружения это означает, что LightGlue видит почти все события на камерах, тогда как старый пайплайн просто не рассматривал заметную часть истории.
Дальше мы посмотрели на большой боевой срез (порядка 50 тыс. пар). Здесь в первую очередь важна разница по покрытию.
Новый детектор обрабатывает почти все возможные пары кадров, фактически весь поток. Старый пайплайн теряет примерно шестую часть пар в основном в сценах с препятствиями в кадре, когда часть полки закрыта людьми, тележками или коробками.
Причина в том, что старый пайплайн на основе SIFT + RANSAC плохо работает при частичных перекрытиях сцены: количество валидных сопоставлений резко падает, оценка трансформации становится нестабильной, и пара фактически «отбрасывается» как нерешаемая.
Новый пайплайн на SuperPoint + LightGlue устойчив к таким ситуациям. Он способен находить корректные соответствия даже при частичной видимости сцены и продолжать обработку пары, явно классифицируя её как WITHOUT, NORMAL или EXTRA, а не теряя её полностью. Для прод-окружения это означает, что LightGlue видит почти все события на камерах, тогда как старый пайплайн просто не рассматривал заметную часть истории.
Вторая важная вещь на боевом срезе - сколько сдвигов мы вообще находим. На одном и том же периоде новый детектор находит сдвиг примерно в тринадцати процентах пар, старый только в районе трёх процентов. То есть новый пайплайн вытаскивает из потока примерно в четыре с лишним раза больше сдвигов. Это не про «галлюцинации», а про то, что раньше значительная часть реальных движений камеры просто складывалась в «ничего не произошло». Если снова посмотреть на распределение по классам, но уже на этом большом датасете, логика остаётся той же. У LightGlue основная часть пар по-прежнему в without, рядом стоит заметный столбик normal на уровне двузначного процента, а high и unknown остаются небольшим хвостом. У старого детектора столбик without раздувается почти до всего набора, normal превращается в узкую полоску, high и unknown на похожем уровне, но за счёт этого нормальные сдвиги оказываются недодетектированы и прячут ся внутри «камеру не трогали».
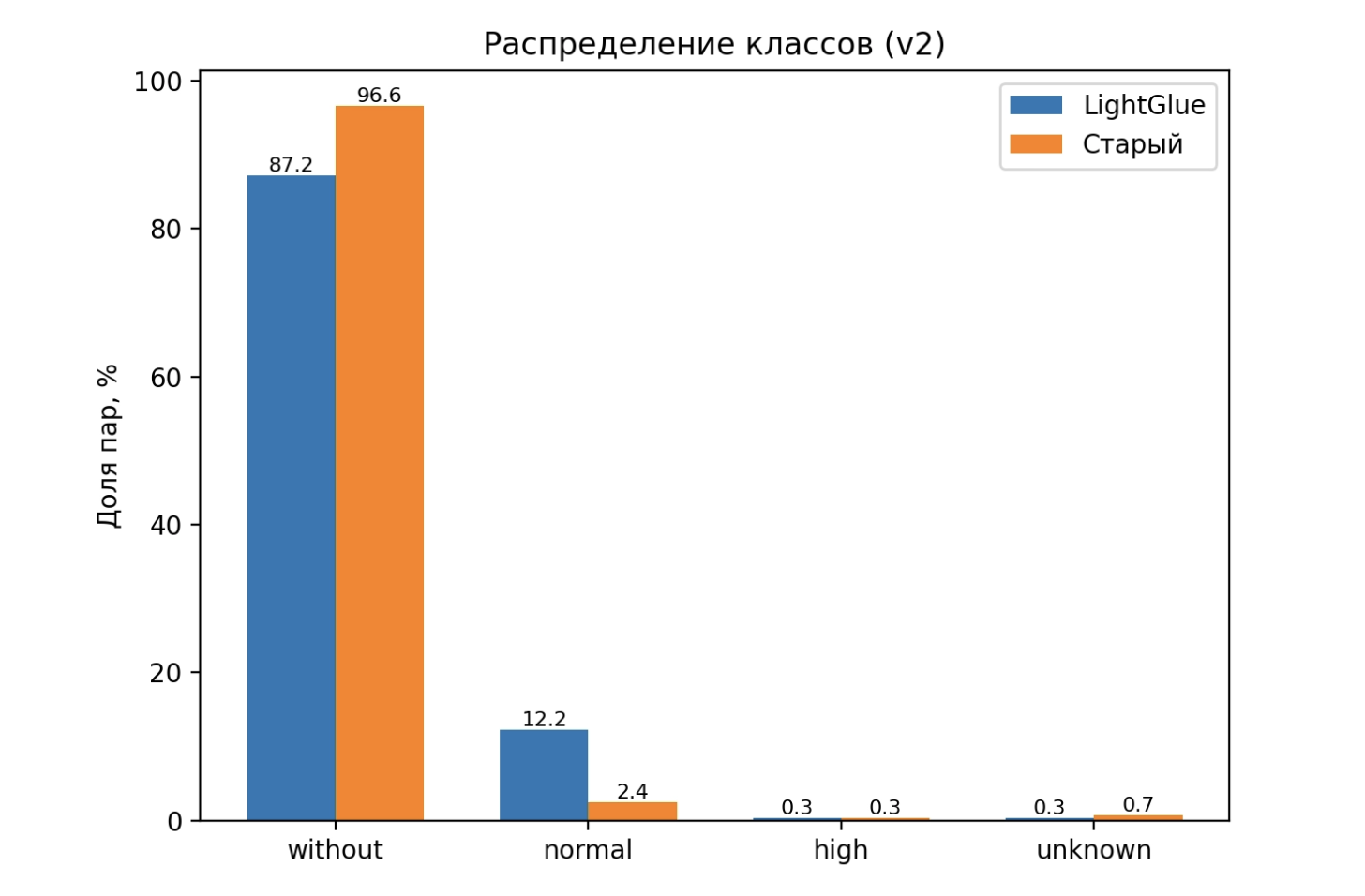
Распределение классов на боевом датасете (LightGlue vs старый детектор)
Разбор отдельных кейсов показывает, откуда именно берётся выигрыш. Новый детектор заметно лучше ведёт себя на сложных сценариях: перспективные и диагональные сдвиги, небольшие повороты камеры, сцены с частичными обстаклами, когда часть полки видна, а часть закрыта. Старый пайплайн в таких ситуациях либо вообще не находил сдвиг и относил всё к without, либо поднимал сомнительный high. LightGlue за счёт более устойчивого матчинга и проверки по оборудованию даёт гораздо более честную картину того, как на самом деле двигаются камеры в проде.
Влияние на модерацию и бизнес-метрики
С точки зрения бизнеса нас интересовали не только метрики по accuracy/recall, но и:
- сколько задач прилетает модераторам;
- насколько можно доверять автосдвигу вьюпортов.
По одной из оценок эффекта внедрения метода (ещё на ResNet+rules-стадии):
- без классификатора: 600 задач модера (high + unknown);
- с классификатором (without + пороги): 156 задач (–35%);
- классификатор + autofix: 86 задач (–45%).
С переходом на LightGlue-пайплайн и детектор оборудования:
- вырос recall по нормальным сдвигам (мы стали видеть гораздо больше реальных сдвигов);
- уменьшилось количество пропусков из-за препятствий;
- снизилось количество «пустых» задач mod-команде, когда камера стоит на месте, а алгоритм думает, что был сдвиг (особенно на сменах ассортимента).
Обсуждение
Если посмотреть на эволюцию детектора сдвигов камеры целиком, можно выделить несколько важных уроков.
- Геометрия важнее контента. Попытка «отдать всё нейросети» (ResNet по дельта-картинке) показала, что модель отлично видит изменения в содержимом полки, но это не всегда коррелирует с геометрическим сдвигом камеры. Нужен баланс: геометрические методы + разумные нейросетевые компоненты.
- Простые эвристики могут дать огромный прирост. Правила на гистограммы SIFT-сдвигов (нулевая доля, толстая дисперсия, разброс по обе стороны) выглядят простыми, но они:
- практически обнулили ложные срабатывания на смену продуктов;
- сильно улучшили качество без тяжёлых моделей.
3._Важно валидироваться на прод-распределении. Отдельные аккуратные датасеты нужны, но только большой прод-срез показывает реальные проблемы: пропуски из-за обстаклов, микросдвиги, редкие corner-кейсы.
4._Детектор сдвигов инфраструктурный компонент. От его качества зависят:
4._Детектор сдвигов инфраструктурный компонент. От его качества зависят:
- корректность работы детектора продуктов;
- нагрузка на модерацию;
- доверие к метрикам по полке.
Заключение и планы
За полтора года детектор сдвигов прошёл путь:
- SIFT + RANSAC + простые пороги быстрый старт, хороший на идеальных полках, но ломается на сменах ассортимента и обстаклах.
- SIFT + гистограммы + эвристики дешёвое и очень эффективное улучшение, резко уменьшившее ошибки на сменах продуктов.
- ResNet + Template Matching попытка забрать часть логики в нейросеть, улучшившая работу с нормальными/сильными сдвигами и сократившая задачи модерации, но оказавшаяся чувствительной к изменению товаров.
- SuperPoint + LightGlue + детектор оборудования современный пайплайн с меньшим числом порогов и ветвлений, который:
- обрабатывает почти все пары кадров;
- в 4.5 раза лучше видит сдвиги;
- перестаёт бояться obstacles.
Дальше мы видим несколько направлений развития:
- более точная оценка микросдвигов (на уровне нескольких пикселей) и их влияние на детектор продуктов;
- улучшение схемы автофиксов (когда можно безопасно сдвигать вьюпорты без модера);
- унификация пайплайна с другими задачами компьютерного зрения (например, с детектором оборудования и сценографией магазина).
Огромное спасибо нашим инженерам, Александру Коротаевскому и Артему Сметанину, за подготовленную статью.

