


В современной розничной торговле автоматизация процессов выкладки и контроля товаров становится критически важной задачей. Системы компьютерного зрения позволяют отслеживать состояние полок в реальном времени, но для их эффективной работы необходима качественная разметка данных – процесс, который является одним из самых дорогих этапов в разработке ML-систем. Понимание того, какие полки действительно требуют переразметки, а какие остались без изменений, позволяет значительно оптимизировать процесс и снизить затраты. Вместо того чтобы размечать все полки с одинаковой частотой, можно сфокусироваться на тех, где произошли реальные изменения или потенциальные ошибки.
В этой статье расскажем о разработке системы на основе CatBoost, которая помогает принимать решения о необходимости разметки, решая три ключевые задачи:
- Определение новых товаров – детектирование товаров, которые появились на полке впервые и требуют внимания разметчиков.
- Поиск потенциальных ошибок реранкера – выявление случаев, когда реранкер (модель, предсказывающая класс продукта) мог ошибиться, и разметчик исправил его предсказание (например, если в месте, где всегда стояли приправы, реранкер предсказал чипсы, а разметчик исправил на приправы).
- Определение «холодных» разметок – выявление случаев, когда содержимое полки скорее всего не изменилось и переразметка не требуется.
Постановка задачи
Бизнес-контекст: процесс разметки
Система работает с данными от камер, установленных в больших сетевых магазинах. Камеры делают фотографии полок, которые затем размечаются вручную или автоматически. Каждая разметка содержит информацию о:
- координатах товаров (bounding boxes);
- идентификаторах товаров (product_id);
- временных метках;
- метаданных (ID полки, камеры, магазина).
Как происходит процесс разметки сейчас:
- Начальный этап: когда система устанавливается в новый магазин, разметка каждой полки происходит каждый день для накопления данных и обучения моделей.
- Оптимизация по сложности: после накопления достаточного объема данных полки делятся на категории сложности на основе F-score качества классификации товаров на этих полках:
- сложные полки (F-score < 80%) – размечаются каждые 3 дня;
- средние полки (F-score 80–95%) – размечаются каждые 5 дней;
- простые полки (F-score > 97%) – размечаются каждые 7 дней.
Такая категоризация позволяет оптимизировать ресурсы, фокусируясь на сложных полках, где модель работает хуже.
Проблемы текущего подхода
Однако даже с указанной оптимизацией возникают ситуации, требующие дополнительного внимания:
- Появление новых товаров: иногда на полке появляются новые товары, которые не были учтены в расписании разметки. Такие случаи нужно своевременно детектировать и отправлять на внеплановую разметку.
- Полки, которые не меняются: напротив, некоторые полки очень редко меняются, и их не нужно переразмечать с заданной частотой – разметка таких полок становится лишней затратой.
- Потенциальные ошибки реранкера: возникают ситуации, когда реранкер (модель, предсказывающая product_id для каждого кропа) делает неправильные предсказания, и человек-разметчик исправляет эти ошибки.
Решение
У нас есть богатая мета-информация о полках: история товаров на этих полках из разметки, данные о складах (остатки товаров), результаты работы реранкера (модели, которая ранжирует кандидатов на product_id), временные метки и паттерны изменений. Мы решили использовать эти данные для создания алгоритма, который позволит еще больше оптимизировать процесс разметки, снизив затраты и повысив качество данных.
Архитектура решения
Мы выбрали CatBoost (градиентный бустинг на деревьях решений) для решения задачи классификации сразу по нескольким критериям (multi-label). На основе исторических разметок система предсказывает вероятность, что товар является новым, что он был неправильно размечен, и что полка не изменилась. Общая архитектура состоит из последовательных этапов:
Создание таргетов (по данным разметки)
↓
Формирование признаков (реранкер, остатки, история)
↓
Обучение моделей CatBoost
↓
Валидация и оценка качества
Подготовка данных
1. Извлечение и очистка данных. На первом шаге из базовой таблицы разметок извлекаются и очищаются данные. В качестве input выступают метаданные полки (ID камеры, полки, магазина, временные метки), в качестве output – размеченные bounding boxes с координатами и product_id. На этом шаге также устраняются дубликаты и пропуски, приводятся корректные типы данных.
2. Создание таргетов. Далее формируются три таргетных признака на уровне каждого отдельного кропа, используя только данные разметки и историю полки. Это позволяет явно зафиксировать, что мы считаем «новым товаром», «ошибкой разметки» и «холодной» разметкой.
Таргет «новый товар»
Для каждого товара на каждой полке строится хронологический ряд всех его разметок. Первое появление товара на полке помечается как «новый товар», все последующие появления этого же товара на той же полке считаются обычными (таргет=0).

Пример полки с разметкой таргетов в красных боксах товары которые впервые появились на этой полке
Пример фрагмента полки. Красным выделены товары, которые появились на этой полке впервые (таргет has_new_product = 1)
Таким образом, «новый товар» означает именно первое фактическое появление товара на полке по данным разметки.
Примечание: Изначально мы пробовали определять новый товар на уровне магазина (первое появление товара в любом магазине сети), но такой подход показал худший результат. На практике оказалось эффективнее определять новые товары на уровне каждой конкретной полки, что мы и используем в таргете «новый товар на полке».
Таргет «потенциальная ошибка реранкера»
Этот таргет отвечает за поиск потенциальных ошибок классификации. Для каждого кропа мы сравниваем класс товара, который предлагала система (например, реранкер или предыдущая версия модели), с финальным классом, который выставил разметчик. Если разметчик оставил прежний класс, считаем, что разметка не изменилась. Если же разметчик поменял класс товара относительно исходного предложения системы, такой кроп помечается таргетом как потенциальная ошибка. Интуитивно, это те случаи, где модель или предыдущая разметка «ошиблась», а человек ее поправил – именно они особенно ценны для обучения моделей.

Пример фрагмента полки. Желтой рамкой выделена потенциальная ошибка реранкера (таргет bbox_label_modified = 1), когда модель ошиблась в классе товара и человек это исправил
Таргет «холодная разметка»
«Холодная» разметка – ситуация, когда полка фактически не изменилась, и текущую разметку можно было бы не делать. Мы анализируем последовательность разметок полки во времени: для соседних разметок сопоставляем товары по положению (bounding box) и классу. Если на новом снимке в том же месте стоит тот же товар, что и на предыдущем снимке, такой кроп считаем «холодным». Дополнительно учитывается более дальняя история: для полок, которые размечаются раз в 5–7 дней, мы сравниваем не только соседние разметки, но и состояние полки через несколько дней. Если множества товаров на полке совпадают, а схема выкладки не меняется, то разметку можно считать «холодной» целиком.
Почему не бинарный таргет горячая/холодная разметка? Мы не стали объединять все изменения в один класс «горячих» разметок против «холодных», поскольку появление новых товаров и ошибки реранкера – разные по природе явления. Разделение на три отдельных таргета позволяет модели лучше учиться каждому случаю и применять разные метрики и пороги для разных сценариев.
Чтобы таргеты оставались непротиворечивыми, введены очевидные ограничения:
- первое появление товара на полке никогда не может быть «холодным»;
- если кроп помечен как «измененная разметка» (была ошибка модели), он не считается холодным, даже если геометрически похож на прошлый.

Пример полки с разметкой таргетов в зеленых боксах холодные кропы
Пример фрагмента полки. Зелеными рамками выделены «холодные» кропы (таргет is_cold = 1), которые не изменились по сравнению с предыдущей разметкой
В итоге каждый кроп получает понятную тройку таргетов:
- has_new_product — новый ли это товар на полке;
- bbox_label_modified — приходилось ли человеку исправлять класс модели;
- is_cold — можно ли было эту разметку пропустить, потому что ничего не поменялось.
Инженерия признаков
После определения таргетов формируется широкий набор признаков (feature engineering) из трех основных источников: результаты реранкера, динамика складских остатков, история предыдущих разметок.
1. Признаки реранкера. Реранкер – модель компьютерного зрения, которая ранжирует кандидатов классов (product_id) для каждого кропа изображения. Из его выходов мы собираем множество признаков, описывающих уверенность модели, конкуренцию между гипотезами и связь с историей полки. Например, такие признаки как: сколько раз топ-1 предсказанный класс встречается среди ближайших эмбеддингов (меряет «уверенность» модели), средняя позиция этого класса среди кандидатов, максимальные скоры модели и разброс между ними, когда этот товар последний раз встречался на данной полке и т.д. Всего было извлечено несколько десятков различных характеристик из результатов реранкера. Часть этих сигналов напрямую подается на вход модели CatBoost, а часть используется для сглаживания предсказаний (усреднения по нескольким снимкам полки).
2. Признаки по остаткам на складах. Вторая группа признаков описывает динамику остатков товара на складе. Для каждого товара и магазина мы строим временной ряд количества товара на складе и рассчитываем значения с разными лагами по времени (от 0 до 90 дней, например: 0, 1, 3, 5, 7, 14, 28, 60, 90 дней). Каждый такой признак отражает, сколько единиц товара было на складе на начало соответствующего дня. Эти фичи помогают модели понять, является ли товар типичным для данной полки с точки зрения логистики: есть ли он сейчас в стоке, был ли в последние недели и месяцы, и как менялись его остатки со временем.
3. Исторические признаки разметок. Дополнительно мы добавили признаки, основанные на истории разметок самой полки: когда последний раз данный товар появлялся на этой полке, сколько раз он встречался за последние N разметок, и т.п. Такие признаки дают модели информацию о привычном ассортименте конкретной полки.
Обучение моделей и оценка качества
Для решения нашей задачи мы обучили три независимые модели CatBoost – по одной под каждый таргет:
- Модель для определения новых товаров – предсказывает вероятность того, что товар появился на полке впервые.
- Модель для поиска потенциальных ошибок реранкера – предсказывает вероятность того, что разметчик исправит предсказание реранкера.
- Модель для определения «холодных» разметок – предсказывает вероятность того, что кроп не изменился и не требует переразметки.
Все три модели обучаются на одном и том же наборе признаков, но с разными таргетами. Это позволяет каждой модели специализироваться на своей задаче и независимо оптимизировать качество предсказаний. Мы сознательно не стали объединять таргеты в одну мультилейбл-модель, потому что каждая из задач имеет разные характеристики и ценность для бизнеса. Отдельные специализированные модели упростили настройку порогов под важные метрики: например, для новой продукции важен баланс precision/recall, для ошибок – высокая полнота, а для «холодных» разметок – высокая точность. Кроме того, некоторые события могут пересекаться (товар может быть одновременно новым и ошибочно распознанным моделью), что усложнило бы обучениe одной модели с несколькими метками.
Перед обучением данные были подготовлены следующим образом:
- Разделение по времени: датасет разделен на обучающую и валидационную выборки в пропорции 80/20 по времени (первые 80% временной линии – на обучение, последние 20% – на проверку). Такое временное разделение обеспечивает валидность модели на будущих данных, а не на прошлых, и дает более реалистичную оценку качества.
- Обработка пропусков: все пропущенные значения признаков заполнены нулями (CatBoost умеет работать с NaN, но мы явно обработали пропуски для консистентности).
- Фильтрация данных: из обучающей выборки удалены записи, где отсутствуют какие-либо таргеты или ключевые признаки.
Гиперпараметры моделей. По результатам экспериментов выбраны следующие настройки CatBoost:
- Количество итераций: 2500 – достаточно для сходимости модели.
- Скорость обучения: 0.008 – низкий learning rate для более стабильного обучения и лучшей обобщающей способности.
- Глубина деревьев: 9 – позволяет модели улавливать сложные взаимодействия между признаками.
- L2-регуляризация: 18 – помогает предотвратить переобучение.
- Ранняя остановка: 200 итераций – обучение прекращается, если качество на валидации не улучшалось 200 итераций подряд.
Обучение моделей выполнялось на GPU, что ускорило процесс.
Результаты
Метрики качества. Таблица ниже показывает качество на тестовой выборке для всех трех моделей (значения усреднены по полкам за последний месяц тестовых данных):
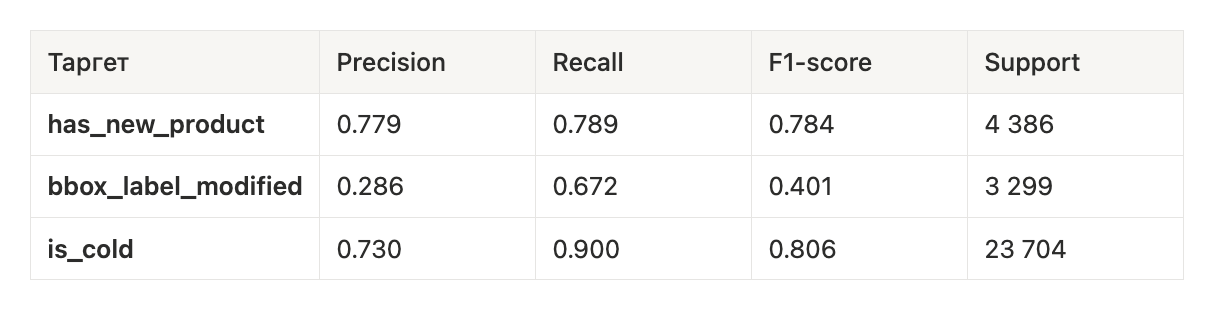
Анализ результатов. Рассмотрим качество каждой модели более подробно:
- Модель для определения новых товаров: F1-score = 0.784 – хороший баланс между точностью и полнотой. Precision = 0.779 означает, что из всех предсказанных моделью новых товаров 78% действительно оказались новыми. Recall = 0.789 означает, что модель находит 79% всех случаев появления нового товара. Модель показывает сбалансированные результаты, что важно для оптимизации процесса разметки (и предотвращает как пропуски новых товаров, так и избыточные ложные тревоги).
- Модель для поиска ошибок реранкера: F1-score = 0.401 – средний результат, что объясняется сложностью задачи. Precision = 0.286 – относительно низкая точность означает много ложных срабатываний, но это допустимо для задачи детектирования потенциальных ошибок. Зато Recall = 0.672 – модель находит ~67% всех случаев, когда разметчик исправил предсказание реранкера. Для этой задачи важнее высокий recall: лучше проверить больше ложных кандидатов, чем пропустить реальную ошибку модели.
- Модель для определения «холодных» разметок: F1-score = 0.806 – лучший результат среди всех трех моделей. Precision = 0.730 – из всех предсказанных «холодных» разметок ~73% действительно не изменились (остальные ~27% оказались не совсем холодными). Recall = 0.900 – модель находит 90% всех холодных случаев. Здесь критически важен высокий precision: пропуск даже нескольких «горячих» разметок (то есть случаев, где полка изменилась, а модель ошибочно решила не размечать) может быть опасен. Поэтому перед внедрением в продакшен для этой модели мы планируем настроить порог более консервативно в сторону точности, в ущерб полноте.
Визуализация и анализ ошибок
Для понимания работы всей системы мы создали модуль визуализации, который наглядно показывает срабатывание моделей на данных. Система отображает одновременно:
- Предыдущую разметку той же полки (для сравнения).
- Ground truth – текущую правильную разметку полки, выполненную человеком.
- Предсказания модели на текущем изображении полки.
Каждый bounding box окрашивается в определенный цвет в зависимости от комбинации таргетов:
- Синий – новый товар (has_new_product = True).
- Оранжевый – потенциальная ошибка реранкера (bbox_label_modified = True).
- Зеленый – «холодная» разметка (is_cold = True).
- Фиолетовый – одновременно новый товар и ошибка реранкера (has_new_product = True и bbox_label_modified = True).
- Красный – обычный товар (никакой особый таргет не сработал).
Ниже приведены реальные примеры работы системы на тестовых данных.

Пример корректной работы модели. На этой полке раньше не было шоколадного мороженого (красные рамки) – как только новый товар появился, модель его обнаружила (синий bounding box на изображении предсказаний).

Еще один пример. В данных разметки были ошибки: между предыдущей разметкой и текущей некоторые пачки чипсов получили другой класс (в ground truth разметчик пометил 4 изменения – красные рамки). Однако на самом деле это одни и те же чипсы, просто переставленные местами. Наша модель верно распознала их как «холодные» (в предсказаниях зелеными рамками выделены 3 кропа, модель не пометила изменения там, где их на самом деле не было).

Пример ошибок детектора. В предыдущей разметке (слева) товары уже присутствовали на полке, но их расположение изменилось к текущему снимку. Несмотря на отсутствие новых товаров, модель ошибочно пометила несколько товаров как «появившиеся впервые» или «измененные» (фиолетовые и оранжевые рамки на изображении предсказаний). Такие случаи выявляются и анализируются для дальнейшего улучшения модели.
Вызовы и решения
При внедрении решения возникли следующие сложности и пути их решения:
- Проблема дрифта данных: модель, обученная на данных за сентябрь, показывает более низкое качество на данных за октябрь–ноябрь.
- Решение: настроено регулярное переобучение модели на новых данных; реализован мониторинг метрик на нескольких валидационных наборах, чтобы своевременно замечать деградацию качества.
- Качество данных: в исходных данных встречаются пропуски, некорректные координаты, дубликаты.
- Решение: добавлена тщательная валидация данных перед обучением; все пропуски заполняются (0 или медианными значениями), дубликаты и заведомо ошибочные записи удаляются.
Выводы и дальнейшие шаги
- Разработана система классификации для определения новых/изменившихся/стабильных товаров на полках с использованием CatBoost.
- Реализована инженерия признаков из различных источников (результаты CV-модели реранкера, данные об остатках товаров, история разметок).
- Достигнуты приемлемые для бизнеса метрики качества модели (F1 от ~0.40 до ~0.80 в зависимости от задачи).
Улучшения на будущее:
- Улучшение моделей для новых товаров: планируем добавить больше признаков, в том числе исторические данные о предыдущих разметках, чтобы улучшить детекцию новых SKU.
- Оптимизация порогов: будем использовать метрики бизнес-ценности (например, экономия часов разметчиков) для тонкой настройки порогов срабатывания моделей вместо простых технических метрик.
- Мониторинг и обслуживание: внедряем систему мониторинга дрифта данных и автоматического переобучения модели, а также проводим A/B-тестирование новых версий моделей перед полноценным запуском.
Заключение
Разработка системы классификации товаров на полках — комплексная задача, требующая глубокого понимания данных, бизнес-логики и методов машинного обучения. Использование CatBoost в сочетании с тщательной инженерией признаков позволило создать рабочую систему, которая помогает автоматизировать процесс разметки товаров в ритейле.
Ключевые моменты:
- Временное разделение данных критически важно для корректной оценки качества модели в условиях, близких к боевым.
- Инженерия признаков из различных источников (CV-модель, складские остатки, история) значительно улучшает качество модели.
- Визуализация ошибок модели помогает быстро находить проблемы и точечно улучшать качество.
- Мониторинг и регулярное переобучение необходимы для поддержания качества модели в продакшене на должном уровне.
Мы надеемся, что наш опыт будет полезен специалистам, работающим над похожими задачами в области компьютерного зрения и ритейла.
Технологии: Python, CatBoost, Pandas, NumPy, scikit-learn, Matplotlib, PIL
Данные: разметки полок крупных сетевых магазинов, период июль–ноябрь 2025
Модели: градиентный бустинг CatBoost на решающих деревьях
Огромное спасибо нашим инженерам, Александру Коротаевскому и Артему Сметанину, за подготовленную статью.

