


Задача
У компании Motul есть основной сайт motul.com и множество сателлитов. На них представлены продукты для пользователей, включая:
Поскольку источников данных множество, маркетинговая команда тратила много времени на сведение данных из разных источников — о посещаемости и метриках всех сайтов, об активности бренда в соцсетях.
- подбор машинного масла и сопутствующих товаров по марке авто;
- поиск реселлера;
- продуктовые страницы с товарами конкретных брендов и марок.
Поскольку источников данных множество, маркетинговая команда тратила много времени на сведение данных из разных источников — о посещаемости и метриках всех сайтов, об активности бренда в соцсетях.
Наша задача заключалась в следующем:
- создать дашборд с ключевыми показателями (KPI) для топ-менеджмента;
- обеспечить команды инструментами для анализа поведения пользователей на сайтах;
- построить конверсионные воронки для ключевых продуктов;
- предоставить инсайты о популярности товаров в разных странах присутствия бренда.
Решение
Скачивание "сырых" данных
Для начала мы собрали данные для анализа.
В качестве хранилища выбрали BigQuery. Источниками данных стали:
Для загрузки информации настроили стек технологий Singer + Meltano.
- шесть сайтов Motul;
- REST API с метаинформацией о контенте продуктовых страниц;
- данные Hookit об активности бренда в соцсетях.
Для загрузки информации настроили стек технологий Singer + Meltano.
Моделирование данных
В процессе анализа сырых данных мы обнаружили неприятный момент: в Google Analytics не всегда реализован трекинг событий. В большинстве случаев доступны только данные о просмотрах страниц через их URL. Однако для дашбордов нам требовалась статистика просмотров с детализацией по товарам, категориям и брендам авто/мото. Это означало, что перед визуализацией данных необходимо было обогатить массив недостающей информацией.
Для проектирования модели данных мы использовали Минимальное Моделирование (minimalmodeling.com) — подход, который позволяет одновременно разобраться в структуре данных и задокументировать ее.
В результате моделирования мы выделили:
Для проектирования модели данных мы использовали Минимальное Моделирование (minimalmodeling.com) — подход, который позволяет одновременно разобраться в структуре данных и задокументировать ее.
В результате моделирования мы выделили:
- анкеры — ключевые сущности предметной области (например, Пользователь, Страница, Бренд);
- атрибуты — характеристики анкеров (например, Название страницы, Дата регистрации пользователя);
- линки — связи между анкерами (например, «Пользователь открыл Страницу»).
Найденные анкеры, атрибуты и линки мы сразу же документируем в excel-файле, что позволило сформировать описание финальных данных еще до реализации.
Итоговая модель данных выглядит следующим образом:
Итоговая модель данных выглядит следующим образом:
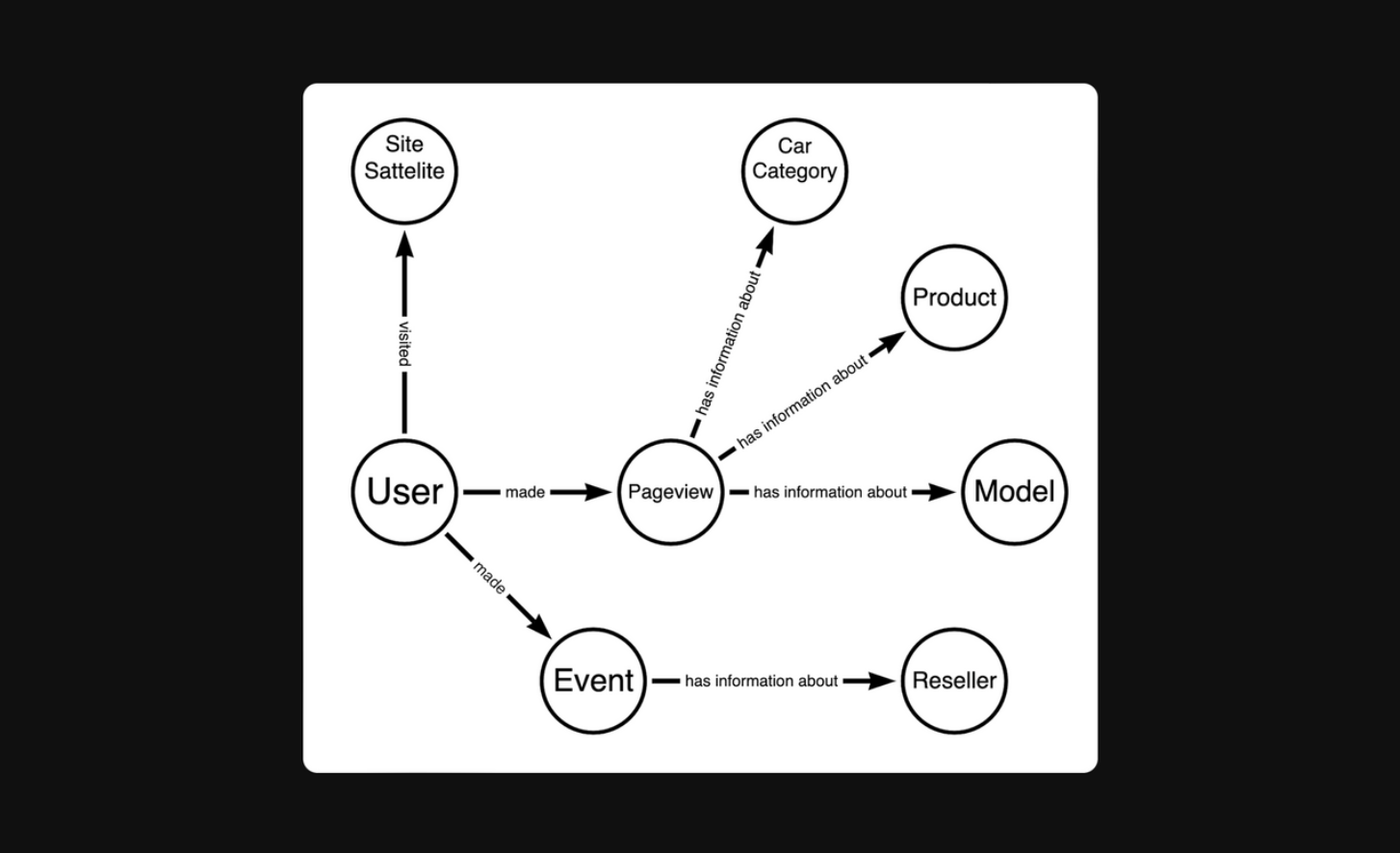
Хотя модель данных оказалась простой с логической точки зрения, установить связи между некоторыми частями данных оказалось тяжело.
Например, выяснить, что пользователь смотрел товар определенной категории можно только разобрав параметры из URL cтраницы. Сложность добавляла разная структура URL в различных разделах сайта.
Например, выяснить, что пользователь смотрел товар определенной категории можно только разобрав параметры из URL cтраницы. Сложность добавляла разная структура URL в различных разделах сайта.
Реализация Data API
На уровне физической реализации все анкеры, атрибуты и линки представлены в виде отдельных независимых таблиц в базе данных.
Такой подход значительно упрощает тестирование: каждая таблица отражает полный граф трансформаций данных. Если возникает ошибка, мы можем отследить её вплоть до исходных данных.
Также если каждый атрибут — это независимая таблица с данными в БД, то к задаче можно подключить сразу несколько аналитиков, которые будут работать над реализацией атрибутов параллельно.
Также если каждый атрибут — это независимая таблица с данными в БД, то к задаче можно подключить сразу несколько аналитиков, которые будут работать над реализацией атрибутов параллельно.
Такие таблицы мы называем Data API, поскольку они представляют собой интерфейс к данным заказчика, который может использоваться для BI-отчетов, ML-моделей и других приложений.
Сбор витрины для Power BI
Поверх данных из data API мы создаём широкие таблицы, предназначенные для визуализации отчетов в Power BI.
При доработке логики работы с сырыми данными, мы меняем только логику в data api, а данные всех широких таблиц для репортинга пересчитываются автоматически.
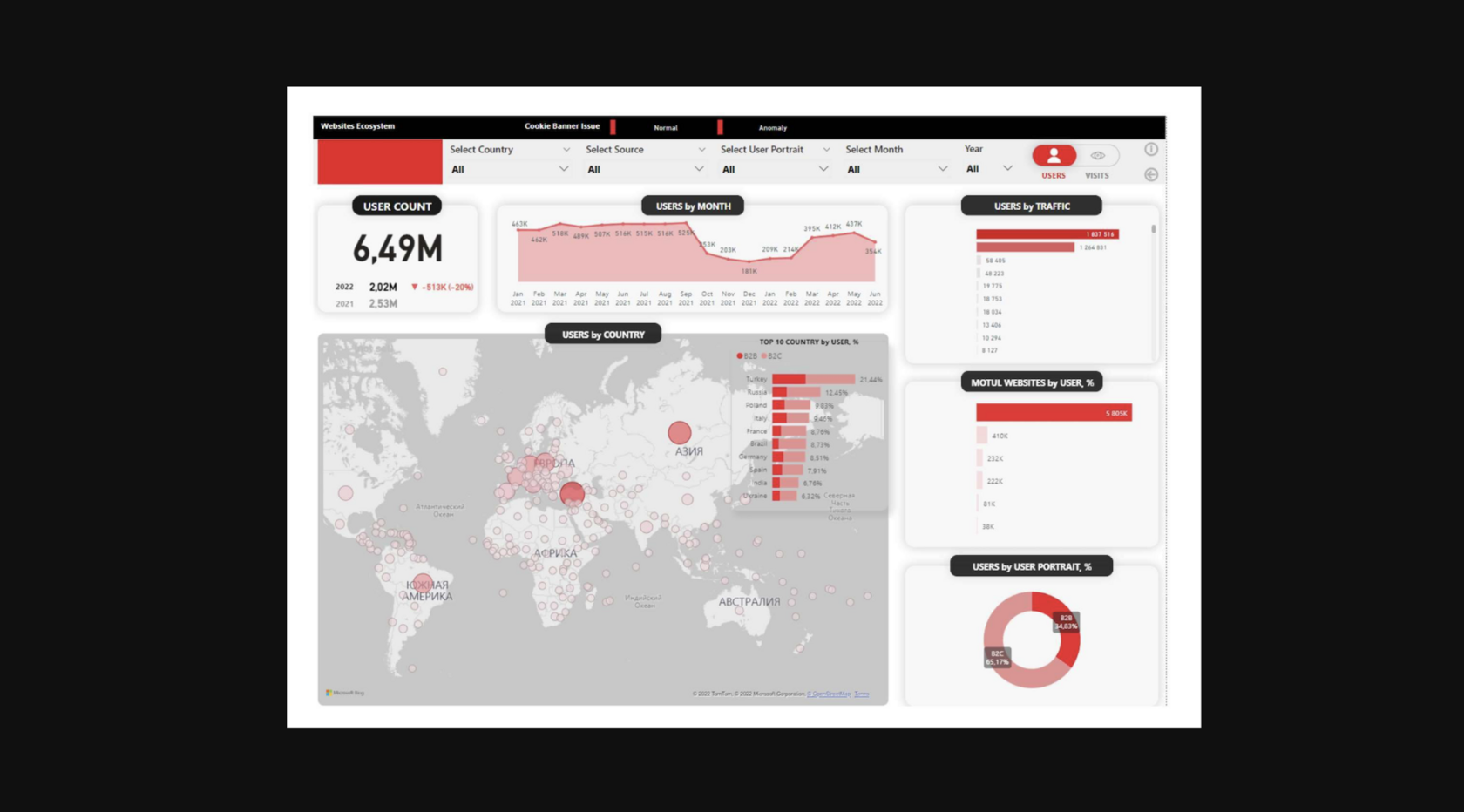
Визуализация данных в Power BI

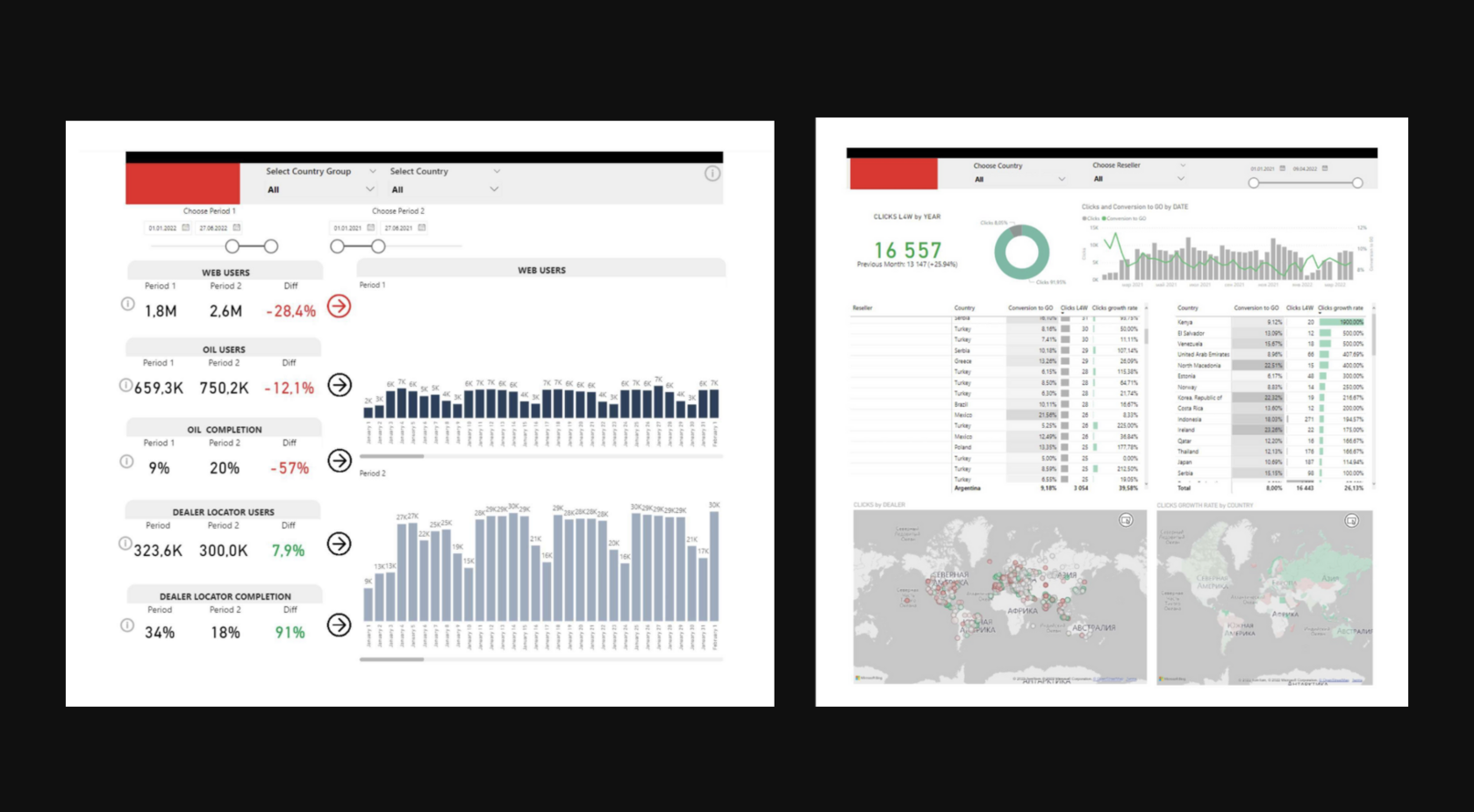
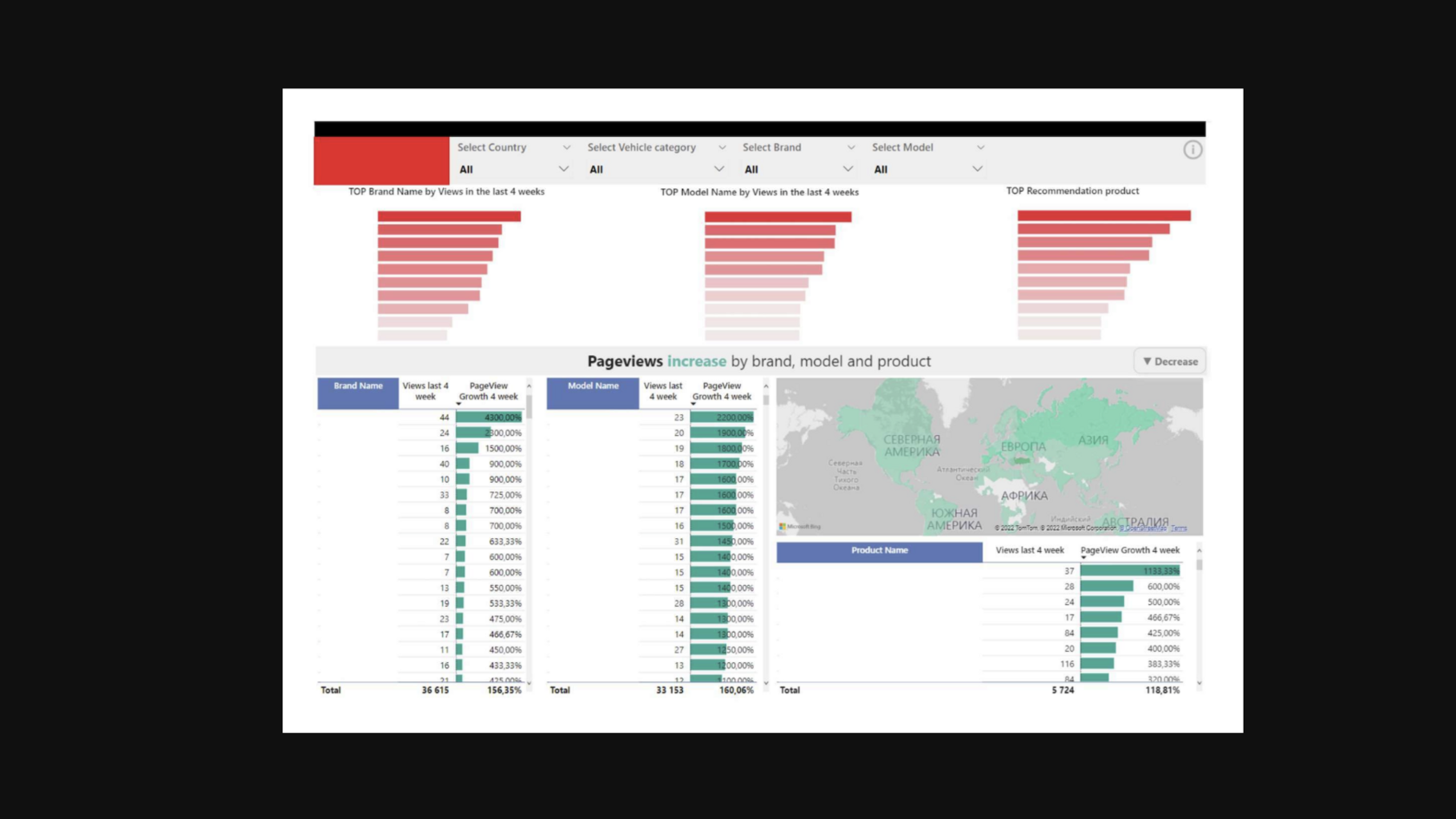
ИТОГИ
В рамках проекта мы:
- собрали данные из всех источников заказчика и обогатили их необходимой для отчетов информацией;
- автоматизировали отчетность по ключевым KPI.

