


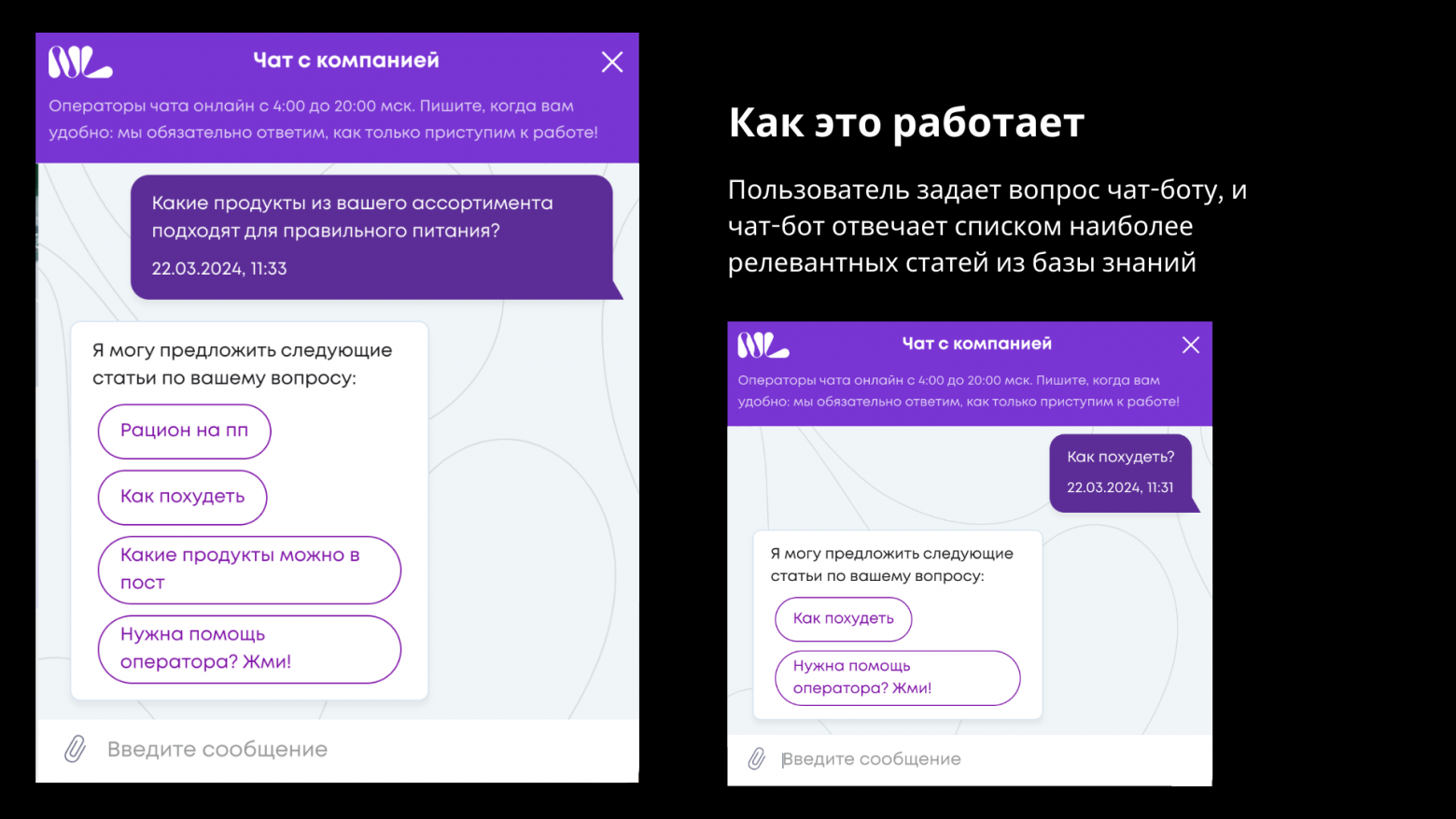
Мы создали виртуального ассистента для NL International, который способен мгновенно отвечать на часто задаваемые вопросы, используя базу знаний компании. Этот ассистент не только выполняет поиск по ключевым словам, но и находит тематически связанные документы, даже если в них отсутствуют точные совпадения по словам.
Например, если пользователь спрашивает: «Я набрал 3 кг за праздничный сезон. Как мне от них избавиться?» — ИИ-ассистент обращается к базе знаний FAQ и находит статью с заголовком «Как похудеть».
Стек
- Chatwoot — интерфейс оператора с открытым исходным кодом и база знаний.
- Rasa — фреймворк с открытым исходным кодом для создания чат-ботов.
- Botfront — визуальный интерфейс для создания чат-ботов на RASA.
- Qdrant — векторная база данных для хранения векторных представлений статей из базы знаний.
- Datapipe — ETL, с помощью которого мы извлекаем статьи из Chatwoot, обрабатываем их и помещаем в Qdrant.
ПРОЦЕСС
1. Контент: Подготовка базы знаний
Мы любим использовать Chatwoot в наших проектах. Обычно мы используем его для интерфейса оператора, когда чат-бот переключается на человека. Но кроме интерфейса оператора, у Chatwoot есть удобная функция базы знаний.
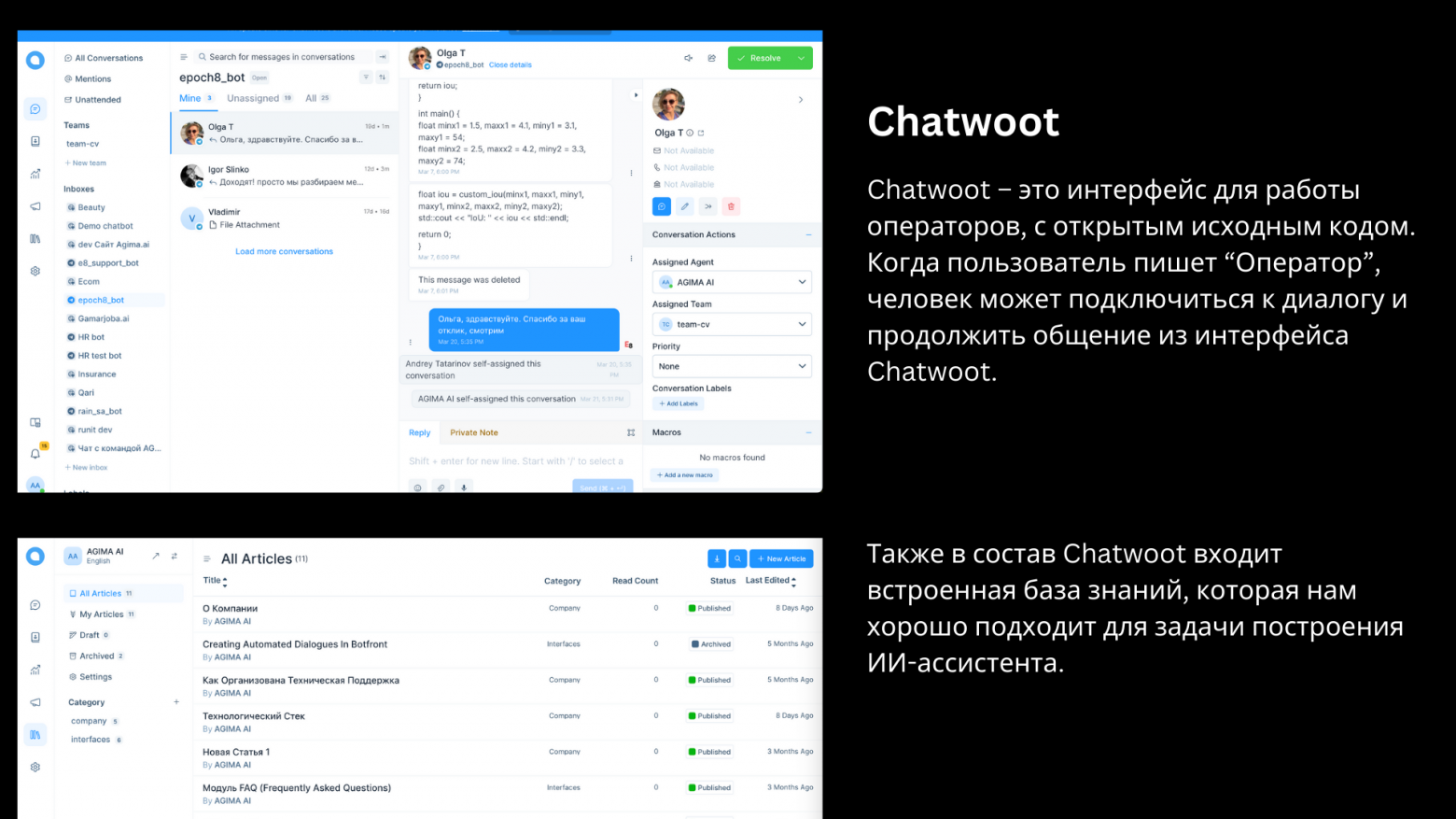
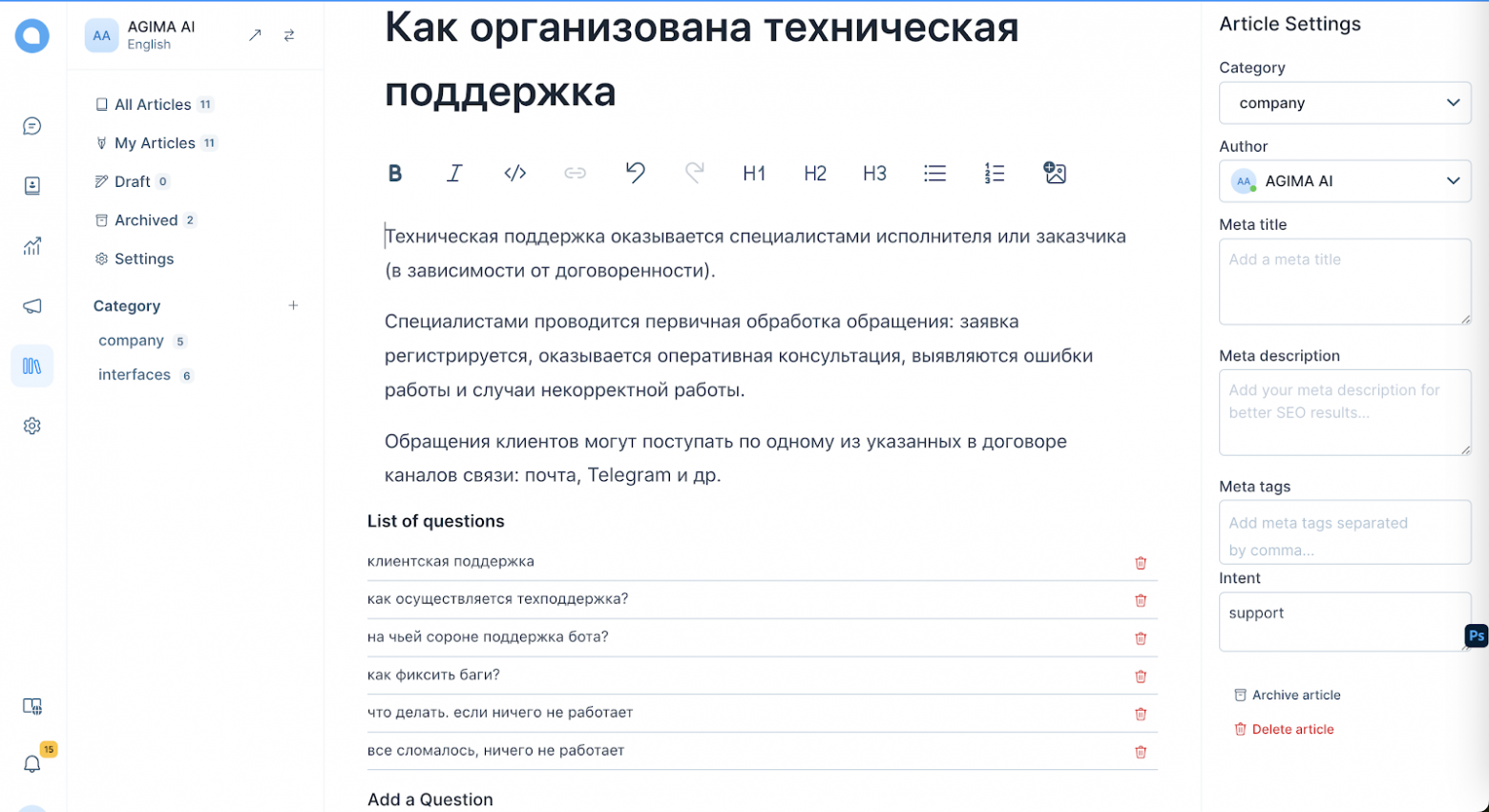
Мы добавили такую функцию в базу знаний Chatwoot: для каждой статьи FAQ мы включаем несколько примеров реальных вопросов, которые пользователи задают, если они хотят получить ответ из этой статьи.
2. Программирование: Преобразование всех статей из базы знаний в векторный вид
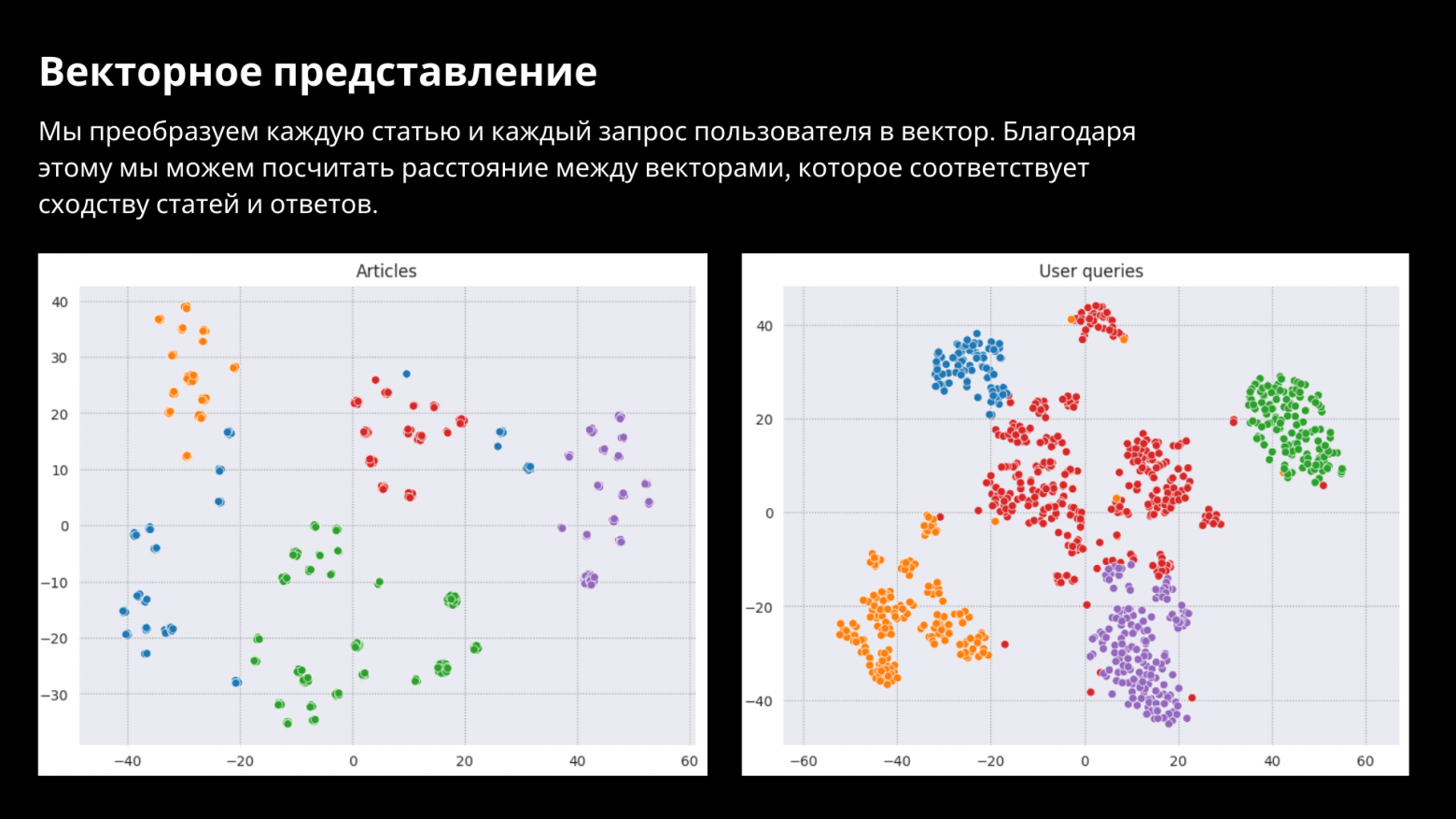
Мы будем искать статьи, которые отвечают на вопрос пользователя по семантическому сходству между текстами. Для этого мы сначала преобразуем тексты в векторный вид, а затем вычисляем расстояние между векторами. Чем меньше расстояние, тем ближе содержание статей.
Для хранения векторного представления статей мы используем векторную базу данных Qdrant. Qdrant оптимизирован для операций с векторами, что позволяет быстро находить схожие вектора.
Для хранения векторного представления статей мы используем векторную базу данных Qdrant. Qdrant оптимизирован для операций с векторами, что позволяет быстро находить схожие вектора.
Чтобы преобразовать текст статьи в вектор и записать его в Qdrant, нам нужно решить две задачи:
- Документы должны быть сегментированы так, чтобы каждый вектор соответствовал одной логической теме. Это важно, потому что чем больше текста кодируется, тем более средним и нечетким становится полученный вектор. Соответственно, становится сложнее определить какую-либо тему в нем. Поэтому важно изначально сегментировать документ на части, и здесь нет универсального решения. Обычно сегментация выполняется с использованием некоторых структурных эвристик (главы или абзацы), затем уточняется моделями для предсказания следующего предложения (NSP), например. И в конечном итоге проверяется человеком.В контексте FAQ этот шаг не понадобился, так как у нас были только короткие ответы. Тем не менее, для обогащения поля поиска мы сгенерировали человекоподобные вопросы к ответам, а для вопросов (если таковые имелись) создали синтетическое «изображение ответа». Все это затем преобразуется в вектор и добавляется в примеры для целевой статьи.
- Нам нужно выбрать эффективный метод генерации векторов. Мы использовали кодировщик от OpenAI или multilingual-e5 модель. Обе они эффективны благодаря их обучению на параллельных корпусах текстов на нескольких языках.
3. Программирование: настройка сервиса FAQ
Сам сервис FAQ реализует простой API. API получает запрос пользователя, преобразует его в вектор и выполняет векторный поиск в Qdrant. Возвращает самые релевантные вектора вместе с заголовками и текстами статей.
4. Программирование: настройка чат-бот ассистента
Нам нужен чат-бот, чтобы получать вопросы от пользователей и отправлять ответы.
Для создания базового чат-бота мы используем Rasa, фреймворк с открытым исходным кодом, и Botfront, визуальный интерфейс.
Для создания базового чат-бота мы используем Rasa, фреймворк с открытым исходным кодом, и Botfront, визуальный интерфейс.
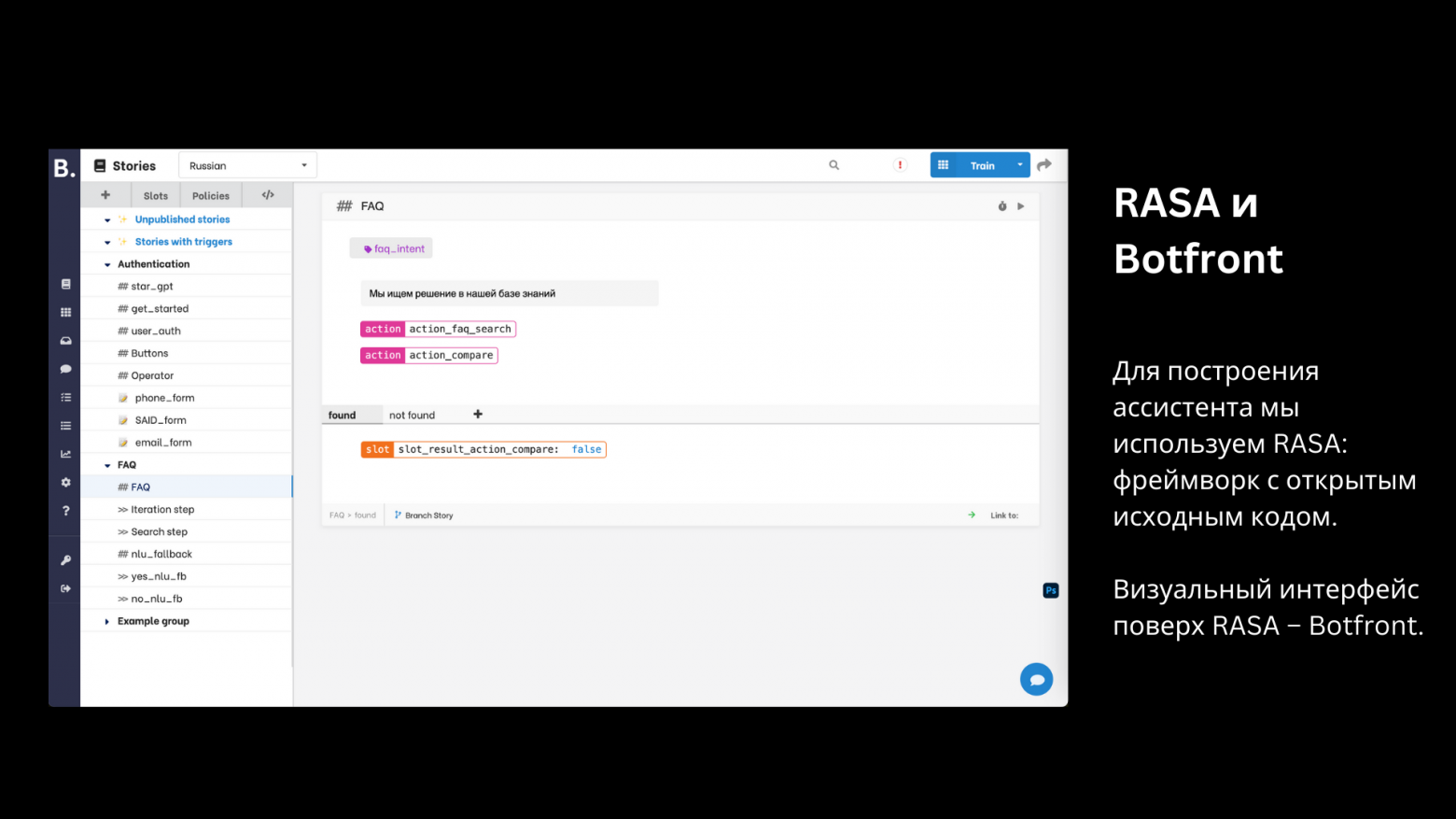
Когда пользователь пишет чат-боту, RASA пытается определить интент в запросе пользователя. Если интент пользователя — задать FAQ-вопрос, RASA перенаправляет запрос в сервис FAQ.
А сервис FAQ возвращает список связанных статей.
А сервис FAQ возвращает список связанных статей.
5. Опционально: ответы в свободной форме с помощью LLM (используя RAG, Retrieval-augmented Generation)
Когда мы извлекли наиболее релевантные статьи из базы знаний, мы можем попросить LLM прочесть извлеченные статьи и сгенерировать точный ответ на вопрос пользователя.
У этого подхода есть серьезный недостаток: лучшие LLM, такие как GPT-4, довольно дорогие, и если у вас большое количество запросов на поддержку, использование LLM может обойтись в крупную сумму.
У нашего клиента был ровно этот случай, поэтому мы отключили генерацию ответов, оставив только ответы списком статей из базы знаний. Такой подход не используют дорогие LLM для каждого запроса.
У этого подхода есть серьезный недостаток: лучшие LLM, такие как GPT-4, довольно дорогие, и если у вас большое количество запросов на поддержку, использование LLM может обойтись в крупную сумму.
У нашего клиента был ровно этот случай, поэтому мы отключили генерацию ответов, оставив только ответы списком статей из базы знаний. Такой подход не используют дорогие LLM для каждого запроса.
6. Программирование: обеспечение актуальности всего
У нас есть регулярные задачи, которые мы должны выполнять, чтобы все данные оставались актуальными.
Мы должны обновлять векторное представление статей в Qdrant, если появляются новые статьи или меняются старые. Для этого мы используем ETL-фреймворк Datapipe, который автоматически отслеживает обновления, удаления и добавления контента. Мы запускаем процесс ETL каждые 15 минут. И если какое-либо содержимое в базе знаний меняется, Datapipe фиксирует изменения и пересчитывает вектора в Qdrant. Таким образом, новая информация становится доступной чат-боту через 15 минут после добавления в базу знаний.
Мы должны убедиться, что RASA правильно идентифицирует интент FAQ. Когда чат-бот переобучается, RASA фиксирует максимально разнообразный набор данных для охвата всего поля поиска с минимальным количеством примеров и добавляет в обучение.
Мы должны обновлять векторное представление статей в Qdrant, если появляются новые статьи или меняются старые. Для этого мы используем ETL-фреймворк Datapipe, который автоматически отслеживает обновления, удаления и добавления контента. Мы запускаем процесс ETL каждые 15 минут. И если какое-либо содержимое в базе знаний меняется, Datapipe фиксирует изменения и пересчитывает вектора в Qdrant. Таким образом, новая информация становится доступной чат-боту через 15 минут после добавления в базу знаний.
Мы должны убедиться, что RASA правильно идентифицирует интент FAQ. Когда чат-бот переобучается, RASA фиксирует максимально разнообразный набор данных для охвата всего поля поиска с минимальным количеством примеров и добавляет в обучение.
ВЫВОДЫ
В результате проекта у нас есть форк Chatwoot, который поддерживает работу ИИ-ассистента на основе базы знаний Chatwoot «из коробки», без дополнительной разработки.
Если вы используете на своих проектах Chatwoot, особенно без чат-бот-автоматизации, возможно, стоит перейти на наш форк Chatwoot, чтобы включить функциональность ИИ-ассистента.
Если вы используете на своих проектах Chatwoot, особенно без чат-бот-автоматизации, возможно, стоит перейти на наш форк Chatwoot, чтобы включить функциональность ИИ-ассистента.
Статистика
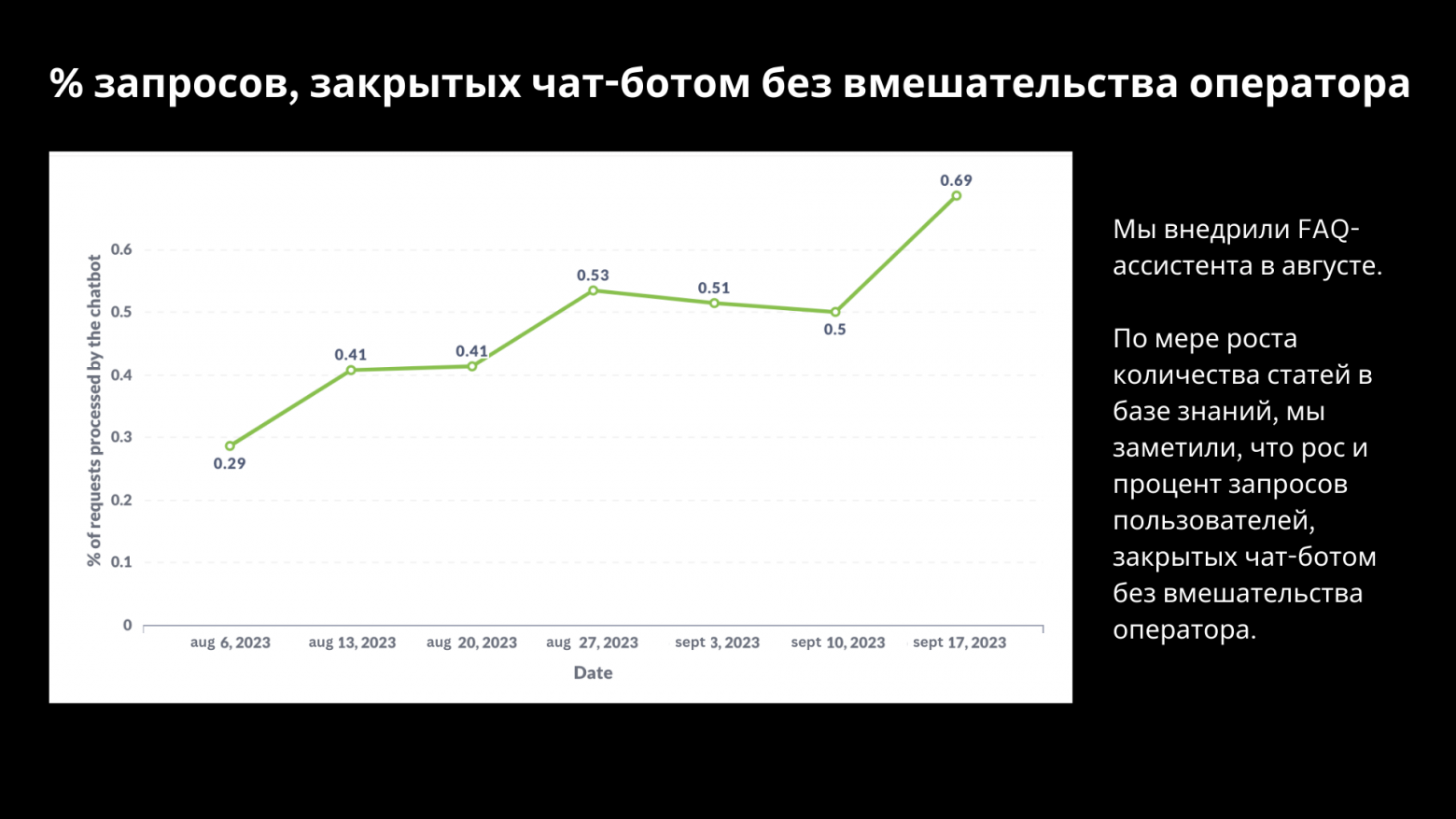
В результате реализации количество запросов на поддержку, обрабатываемых чат-ботом, увеличилось с 30% до 70%. Команда контента продолжает добавлять статьи, чтобы чат-бот мог обрабатывать всё больше и больше запросов.
Команда
- Андрей Татаринов, СТО;
- Мария Родина;
- Рустам Каримов;
- Антон Гречкин;
- Сергей Серов.

