

Продолжение цикла статей о компьютерном зрении для ритейла.
О чем эта статья?
Когда камера фиксирует полку, между объективом и товаром нередко оказывается покупатель, тележка или пакет. Для корректной работы пайплайна классификации товаров система должна уметь обнаруживать такие препятствия и понимать, реально ли они перекрывают товар или просто попадают в кадр на заднем плане. Статья описывает двухуровневый подход к решению этой задачи.
Детекция препятствий на полках
Задача: определить объекты, частично или полностью перекрывающие область полки, для стабильной работы пайплайна. При полном перекрытии выполняется повторное фотографирование; при частичном система выделяет препятствие и исключает его из области анализа.
Данные: фотографии с камер, направленных на полки супермаркета, без дополнительной обработки.

Пример фотографии полки с препятствиями, выделенными в процессе разметки
Подход к решению
Для детекции препятствий на полках мы используем двухуровневый подход на основе глубокого обучения.
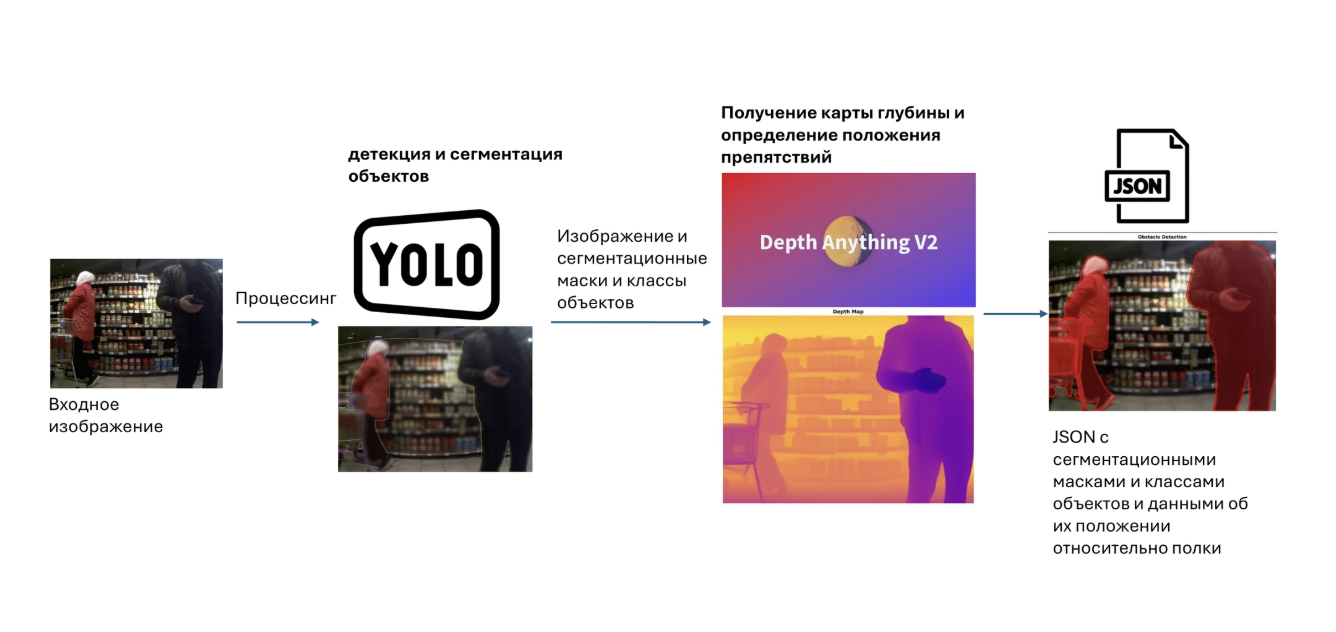
Общая схема пайплайна детекции препятствий
Уровень 1: детекция и сегментация объектов
На первом уровне работает YOLO11 в конфигурации instance segmentation — это позволяет получать пиксельно-точные маски для каждого обнаруженного объекта.
Классы объектов
Модель обучена детектировать и сегментировать 8 классов:
- product — товары на полках
- obstacle — устранимые препятствия, перекрывающие товары
- cart — тележки покупателей
- customer — покупатели
- worker — сотрудники магазина
- obstacle_equipment — оборудование (стеллажи, техника и т. д.)
- obstacle_bag — пакеты
- unknown — неопределённые объекты (неустранимые препятствия)
Такая детализация позволяет не только фиксировать сам факт наличия препятствия, но и классифицировать его тип — что важно для последующего анализа и принятия решений.
Формат разметки
Разметка выполнена в формате YOLO segmentation. Для каждого объекта сохраняется:
- ID класса (0–7)
- полигон объекта в нормализованных координатах (x, y ∈ [0; 1])
Изначально датасет был размечен только bounding boxes. Для перехода к полигональной разметке мы использовали полуавтоматический пайплайн: YOLO детектировал bbox, SAM (Segment Anything Model) по этим областям генерировал маски, после чего разметка доаннотировалась вручную.

Пример полученной разметки через пайплайн Yolo + SAM2
Почему instance segmentation, а не bounding box
Более точная локализация. Маска передаёт форму объекта, а не только его прямоугольное обрамление — это критично при анализе частичного перекрытия товара.
Корректная оценка перекрытия. Площадь пересечения товара и препятствия вычисляется по маскам, а не по bbox. Это существенно снижает погрешность — особенно для вытянутых или произвольно ориентированных объектов.
Уровень 2: определение положения препятствий
Сегментации первого уровня недостаточно для практического применения: маски показывают, что за объект находится в кадре и где он проецируется на изображение, но не отвечают на вопрос — находится ли препятствие перед товаром или позади него.
На полках это принципиально важно. В 2D-проекции объект за полкой — например, покупатель в проходе или тележка на соседней линии стеллажей — может визуально «перекрывать» маску продукта, хотя в реальности доступ к товару он не блокирует. Если опираться только на сегментацию, такие объекты будут ошибочно считаться препятствиями и генерировать ложные срабатывания дальше по пайплайну.
Второй уровень решает эту проблему: он использует информацию о глубине сцены, чтобы:
- отфильтровать препятствия, находящиеся за плоскостью полки;
- определить относительное положение каждого препятствия (перед/за/между) относительно продуктов.
Архитектура модели
Для оценки глубины используется предобученная модель Depth Anything V2 на базе Vision Transformer. Архитектура включает энкодер (ViT) и декодер DPT (Dense Prediction Transformer), который преобразует многомасштабные признаки в карту глубины с разрешением исходного изображения. Карта инвертируется так, что ближним к камере объектам соответствуют более высокие значения — это упрощает дальнейший анализ.
Для каждого продукта, заданного bounding box, система вычисляет референсное значение глубины. Алгоритм использует адаптивный подход:
- если центр bbox не перекрыт препятствием — берётся среднее значение глубины в окне 5×5 пикселей вокруг центра;
- если центр перекрыт — глубина усредняется по всей площади bbox за исключением зон, закрытых препятствиями.
Классификация препятствий
Каждое препятствие (заданное полигоном) классифицируется относительно продукта в три шага.
Шаг 1: геометрическое пересечение. Вычисляется маска препятствия и проверяется её пересечение с bbox продукта. Если пересечения нет — препятствие исключается из анализа.
Шаг 2: геометрические эвристики. Если площадь пересечения превышает 80% площади препятствия или препятствие выходит за нижнюю границу продукта — оно классифицируется как находящееся перед продуктом.
Шаг 3: анализ распределения глубины. По области препятствия вычисляется доля пикселей с глубиной меньше референсной глубины продукта. Затем применяются пороговые значения:
- более 70% таких пикселей → препятствие перед продуктом
- менее 30% → препятствие за продуктом
- промежуточный случай → между или неизвестно
Метрики и альтернативные эксперименты
Оценка качества модели
Для оценки качества используется комбинация классических метрик компьютерного зрения и бизнес-метрик, отражающих реальную ценность системы.
Метрики детекции:
- Precision (PR) — доля корректно распознанных препятствий среди всех предсказаний модели.
- Recall (RC) — доля обнаруженных препятствий среди всех реально существующих.
- F1-score — гармоническое среднее Precision и Recall.
Достигнутые результаты лучшей модели:
Бизнес-метрики:
При расчёте бизнес-метрик учитываются только препятствия, пересекающие зону расположения товаров — остальные не влияют на работу пайплайна и считаются незначимыми.
- Accuracy — общая точность классификации с учётом бизнес-ограничений: 0.9415 (94.15%).
Проблема: «вырезанные» маски при перекрытиях
В реальных сценах классы часто пересекаются пиксельно: покупатель, сотрудник, тележка, пакеты и другие препятствия могут накрывать товары. Для нашего пайплайна это критично — дальше мы используем геометрию и площадь пересечения масок, чтобы определить факт и степень перекрытия товара препятствием.
На части данных мы столкнулись с характерным артефактом: при пересечении объектов возникали нестабильные (рваные) маски. В частности, маска продукта могла «съедать» маску препятствия или порождать некорректную геометрию в зоне пересечения. Это ухудшало оценку перекрытий и приводило к ошибкам на инференсе: препятствие визуально есть, но его маска частично «пропадает» именно там, где важнее всего — поверх товара.

Пример инференса модели до приоритета классов в разметке
Решение: явная иерархия классов в разметке. Мы ввели приоритизацию: все классы препятствий и «передних» объектов считаются более приоритетными, чем product. Логика простая: пиксели, занятые препятствием, не должны принадлежать маске товара — тогда препятствие не «пробивается» маской продукта и сохраняет целостность контура.
Технически это реализовано как препроцессинг разметки:
- По всем объектам «старших» классов строится объединённая occupancy-маска (union по пикселям).
- Из маски каждого product вычитаются пиксели, занятые препятствиями.
- Если после вычитания маска товара распадается на несколько компонент — находим контуры и сохраняем их как новые полигоны разметки.
- Маски «старших» классов сохраняются без изменений — именно они «побеждают» в конфликте перекрытий.
После введения иерархии мы получили устойчивые маски препятствий без «вырезаний» в зонах перекрытия, более корректную оценку площади перекрытия и меньше нестабильных случаев в логике второго уровня. Явная иерархия в разметке превратила неоднозначные перекрытия классов в детерминированное правило — и это заметно повысило стабильность instance segmentation на практике.

Пример инференса переобученной модели после приоритета классов в разметке
Протестированные архитектуры
В ходе разработки мы проверили несколько альтернативных подходов.
ModelResNet_RGBA — классификатор на базе ResNet18, использующий RGBA-каналы, где альфа-канал передаёт дополнительную информацию о позиции камеры. Это помогает модели лучше понимать контекст сцены и расположение препятствий относительно полки. (исходник)
PSPNet (Pyramid Scene Parsing Network) — сегментационная модель из mmsegmentation, использующая пирамидальный пулинг для учёта контекста на разных масштабах. Хорошо справляется с семантической сегментацией, однако для задачи instance segmentation потребовала существенной дополнительной адаптации. (исходник)
Выбор финальной архитектуры
По итогам сравнительного анализа финальный выбор пал на YOLO segmentation по четырём причинам:
- Оптимальный баланс точности и скорости, критичный для обработки в реальном времени.
- Нативная поддержка instance segmentation, обеспечивающая корректную работу с пересекающимися объектами.
- Простота интеграции в существующий пайплайн.
- Эффективность обучения: высокие результаты без значительных вычислительных затрат.
Визуализации и примеры работы
Первый уровень: сравнение Ground Truth и предсказаний модели

Сравнение результатов детекции модели с эталонной разметкой. Левая панель - Ground Truth, правая панель - предсказания модели.
Впрочем, модель не застрахована от ошибок. Вот пример, где достаточно очевидный человек в кадре не был обнаружен:

Встречаются и более неожиданные случаи — например, ручка от корзинки
Второй уровень: определение положения препятствий

Результаты определения положения препятствий относительно полки с использованием модели второго уровня.
Итоги
В рамках работы был разработан и протестирован двухуровневый пайплайн детекции препятствий на полках розничных магазинов.
На первом уровне модель YOLO segmentation решает задачу детекции и instance segmentation, обеспечивая пиксельно-точную локализацию товаров и потенциальных препятствий. Это позволяет корректно анализировать частичные перекрытия и учитывать сложную геометрию объектов — то, что недостижимо при подходе на основе bounding box.
На втором уровне в пайплайн интегрирован анализ глубины сцены на базе Depth Anything V2. Комбинация геометрических эвристик и анализа распределения глубины позволяет определять положение препятствий относительно плоскости полки и эффективно отфильтровывать объекты, находящиеся за ней, — что существенно снижает количество ложных срабатываний по сравнению с чистой 2D-сегментацией.
Качество системы подтверждено как классическими метриками, так и бизнес-метриками: Precision = 0.84, Recall = 0.746, F1 = 0.788, бизнес-точность – 94.15%. Эти результаты показывают, что система устойчиво работает даже в условиях динамичной сцены с покупателями, тележками и частичными перекрытиями товаров.
Сочетание instance segmentation и анализа глубины оказалось эффективным и масштабируемым подходом для данной задачи. Пайплайн легко интегрируется в существующую инфраструктуру и может быть расширен для смежных задач розничной аналитики: контроля доступности товаров, анализа поведения покупателей, мониторинга состояния торгового пространства.
Огромная благодарность нашим инженерам, – Александру Коротаевскому и Артему Сметанину за подготовленную статью.

