


Задача
Также раз в несколько дней одно фото с каждой камеры попадает в ручную разметку.
Пример фото с камеры ниже:

Типичное фото к с камеры и детекции от YOLO. В самом низу - пример камеры.
Пайплайн v0 (эмбеддер + search space) и v1 (v0 + realgram)
- По детекциям YOLO вырезаем кропы.
- Каждый кроп пропускаем через эмбеддер и получаем векторное представление.
- Ищем ближайший вектор в Qdrant, где хранится search space с эмбеддингами и метаданными размеченных кропов.
- Берём top-1 по cosine similarity и присваиваем класс продукта.
Решение v1 добавляло поверх поиска в Qdrant ещё и realgram — алгоритм, который учитывает то, что было на этой же полке в последних разметках. Если вкратце: для всех товаров из разметки считаем коэффициент устаревания и коэффициент пересечения по координатам, объединяем их и добавляем к cosine similarity из пайплайна v0. В итоге получаем более устойчивый алгоритм, учитывающий больше контекста и повышающий метрику до 92%.
Оставшиеся проблемы
- Качество всё ещё далеко от идеала: на сложных кропах, где плохое освещение или часть товара не видна, мы всё ещё предсказываем почти случайно, опираясь в основном на контекст разметок на полке;
- Большое количество «миганий»: когда на соседних фото с одной камеры товар в каком-то месте не изменился, но предсказание для него меняется из-за волатильности топа search space. В основном эту проблему мы и будем решать в этой статье.
Object tracking
Что такое object tracking и зачем это нужно в нашей задаче
- визуальные признаки объекта;
- динамику его движения.
Главная цель трекинга — понять, какой объект в текущем кадре соответствует объекту из предыдущего кадра, даже если он немного изменил положение, масштаб или внешний вид.
С визуальными дескрипторами или без?
Поэтому особенно важными становятся качественные дескрипторы, устойчивые к изменению ракурса, освещения и положения объектов.
Что такое визуальные дескрипторы?
Визуальный дескриптор — это способ «перевести» изображение объекта в набор чисел, с которым можно работать математически.
Нейросеть берёт картинку и превращает её в вектор — компактное описание внешнего вида объекта.
Идея простая:
- похожие объекты → похожие векторы,
- разные объекты → разные векторы.
Например, одна и та же пачка молока, снятая под разным углом или при другом освещении, будет иметь близкие дескрипторы. А молоко и шоколадка — уже нет.
Решение v2: v1 + tracking
Применяем трекинг в нашей задаче
- повысить стабильность предсказаний,
- уменьшить количество «миганий»,
- потенциально улучшить качество классификации.

Столбец - одно фото с камеры, строка - один набор координат. Конкретно на этой камере товары со временем почти не меняются и выглядят почти идентично, так, что трекинг будет работать хорошо. Но так хорошо дела обстоят далеко не на всех камерах.
Модифицированный DeepSORT
- Во-первых, на полке часто стоят несколько идентичных товаров с почти одинаковыми эмбеддингами, из-за чего легко сматчить неправильные объекты (например, первую бутылку колы на одном кадре со второй бутылкой колы на другом).
- Во-вторых, товары в целом мало перемещаются, а требования к надёжности матчинга достаточно высокие, поэтому разделение IoU-матчинга и матчинга по эмбеддингам оказалось неэффективным — лучше учитывать оба сигнала одновременно.
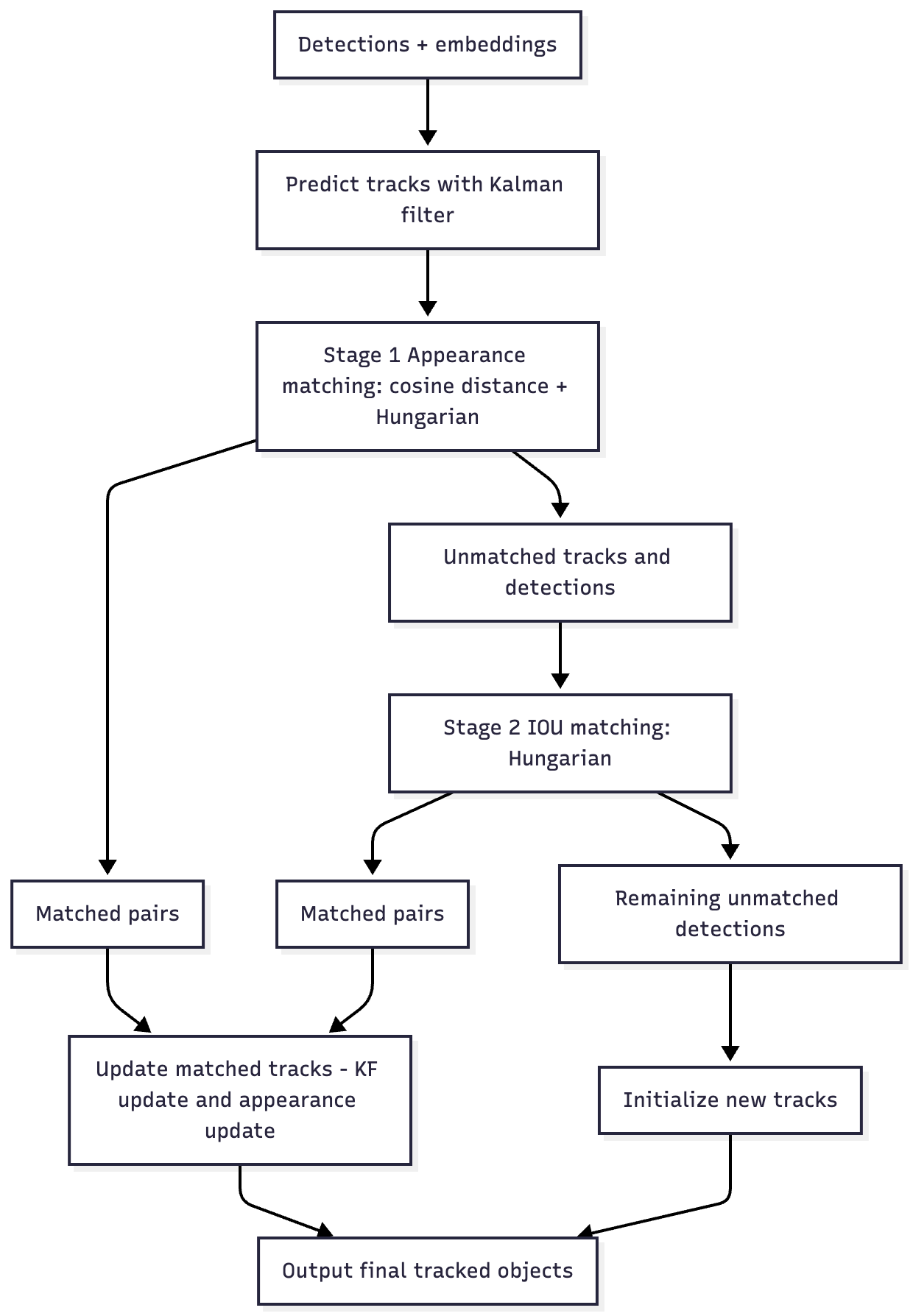
Оригинальный DeepSORT: сначала матчинг по эмбеддингам (убирая нереалистичные фильтром Калмана), а для тех, что не сматчились по эмбеддингам - матчинг по IoU.
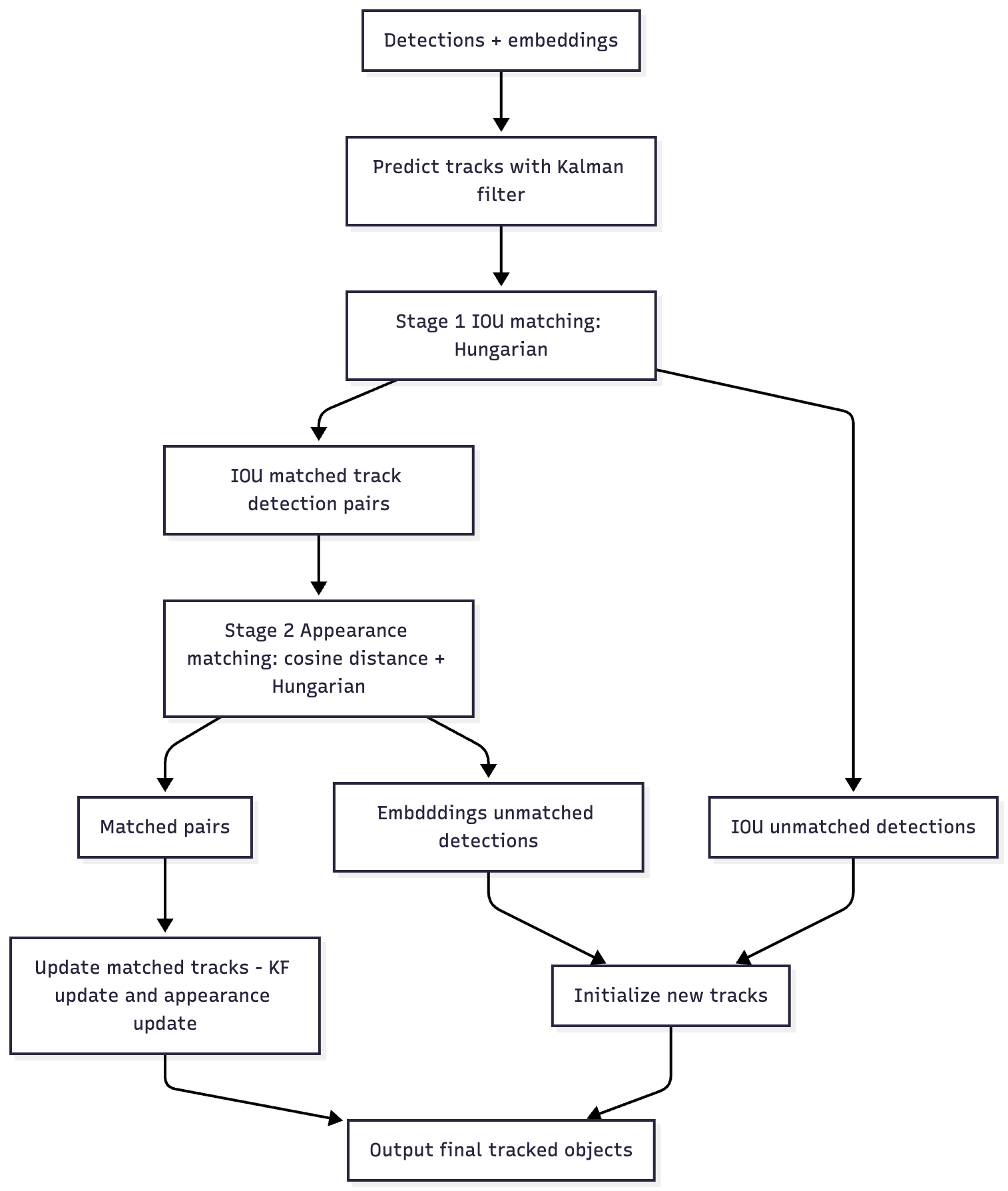
Наша версия DeepSORT: сначала матчинг по IoU, и только для тех, которые сматчились по IoU - матчинг по эмбеддингам (поскольку товары у нас особо не двигаются и нам важнее визуальные дескрипторы).
Пайплайн v2: добавляем трекинг
Про «последнюю неиспользованную разметку».
Делать трекинг между кадрами — хорошая идея, но если источником для трекинга становится обычное предсказание пайплайна (с качеством, например, 90%), то в 10% случаев трекинг будет «тащить» ошибку дальше. Чтобы уменьшить этот эффект, мы используем разметку как более надёжный источник.
На каждом кадре мы проверяем наличие разметки. Когда появляется новая разметка, мы один раз запускаем трекинг от неё и затем продолжаем трекинг на промежуточных кадрах. Да, с каждым кадром число треков, созданных из разметки (мы называем их «якорными»), уменьшается, но в зависимости от порогов между разметками сохраняется от 20% до 50% «якорных» треков.
- Если скор трекинга (IoU между боксами × cosine similarity между эмбеддингами) выше, чем скор промежуточного предсказания минус константа (гиперпараметр, определяющий уровень доверия к трекингу), мы берём предсказание из предыдущего кадра.
- Иначе берём промежуточное предсказание и инициализируем трек этим предсказанием.
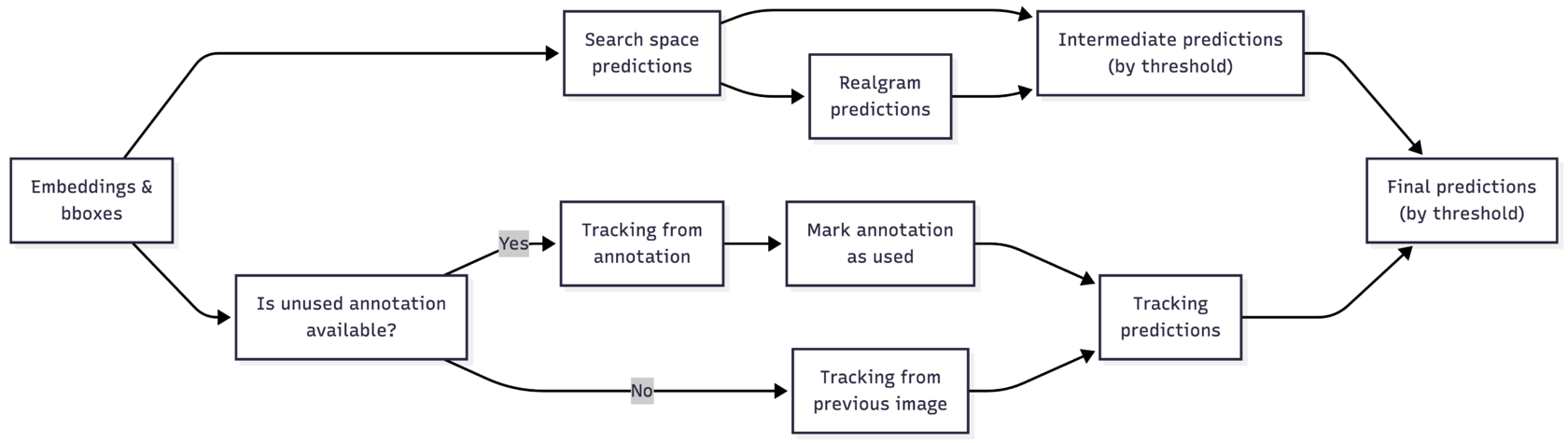
Пайплайн v1 выглядит примерно так: из search space и realgram получаем промежуточные предсказания; получаем предсказания из трекинга; выбираем из них по скору с threshold.
Тем не менее результат есть: метрика (способ её расчёта описан в предыдущей статье) выросла с 92% до 94%, а количество «миганий» снизилось примерно вдвое.
Что касается метрики «миганий», на тот момент мы не вводили отдельную формальную метрику, поэтому оценка их снижения носит качественный характер. Однако эффект хорошо объясним: после добавления трекинга предсказание на текущем кадре значительно чаще наследуется от предыдущего, тогда как раньше соседние кадры обрабатывались независимо. В результате совпадение предсказаний между соседними кадрами стало происходить заметно чаще, что визуально снижает количество «миганий».
Результаты
- Рост числа гиперпараметров. У realgram их было около 10, трекинг добавил ещё примерно 5. Даже Optuna перестала эффективно справляться с поиском, а риск оверфиттинга вырос, поскольку подбор параметров каждый раз выполняется на ограниченном датасете.
- False positive трекинга. Даже при высоком скоре трекинг может «тащить» ошибочные предсказания. Например, в тех же координатах один товар может смениться другим вкусом или ароматом, визуально почти не отличимым. В такой ситуации трекер легко подхватывает неправильный класс.
- Усложнение выбора между кандидатами. С добавлением трекинга мы ещё больше усложнили проблему выбора: теперь у нас есть множество кандидатов — из top search space, realgram и трекинга. Их может быть один, а может быть двадцать. Как выбирать между ними?

